An Efficient 3D CNN for Action/Object Segmentation in Video
Rui Hou, Niantic Labs, houray@gmail.com
Chen Chen, UNC-Charlotte, chen.chen@uncc.edu
Rahul Sukthankar, Google Research, sukthankar@google.com
Mubarak Shah, University of Central Florida, shah@crcv.ucf.edu
Abstract
Convolutional Neural Network (CNN) based image segmentation has made great progress in recent years. However, video object segmentation remains a challenging task due to its high computational complexity. Most of the previous methods employ a two-stream CNN framework to handle spatial and motion features separately. In this paper, we propose an end-to-end encoder-decoder style 3D CNN to aggregate spatial and temporal information simultaneously for video object segmentation. To efficiently process video, we propose 3D separable convolution for the pyramid pooling module and decoder, which dramatically reduces the number of operations while maintaining the performance. Moreover, we also extend our framework to video action segmentation by adding an extra classifier to predict the action label for actors in videos. Extensive experiments on several video datasets demonstrate the superior performance of the proposed approach for action and object segmentation compared to the state-of-the-art.Method
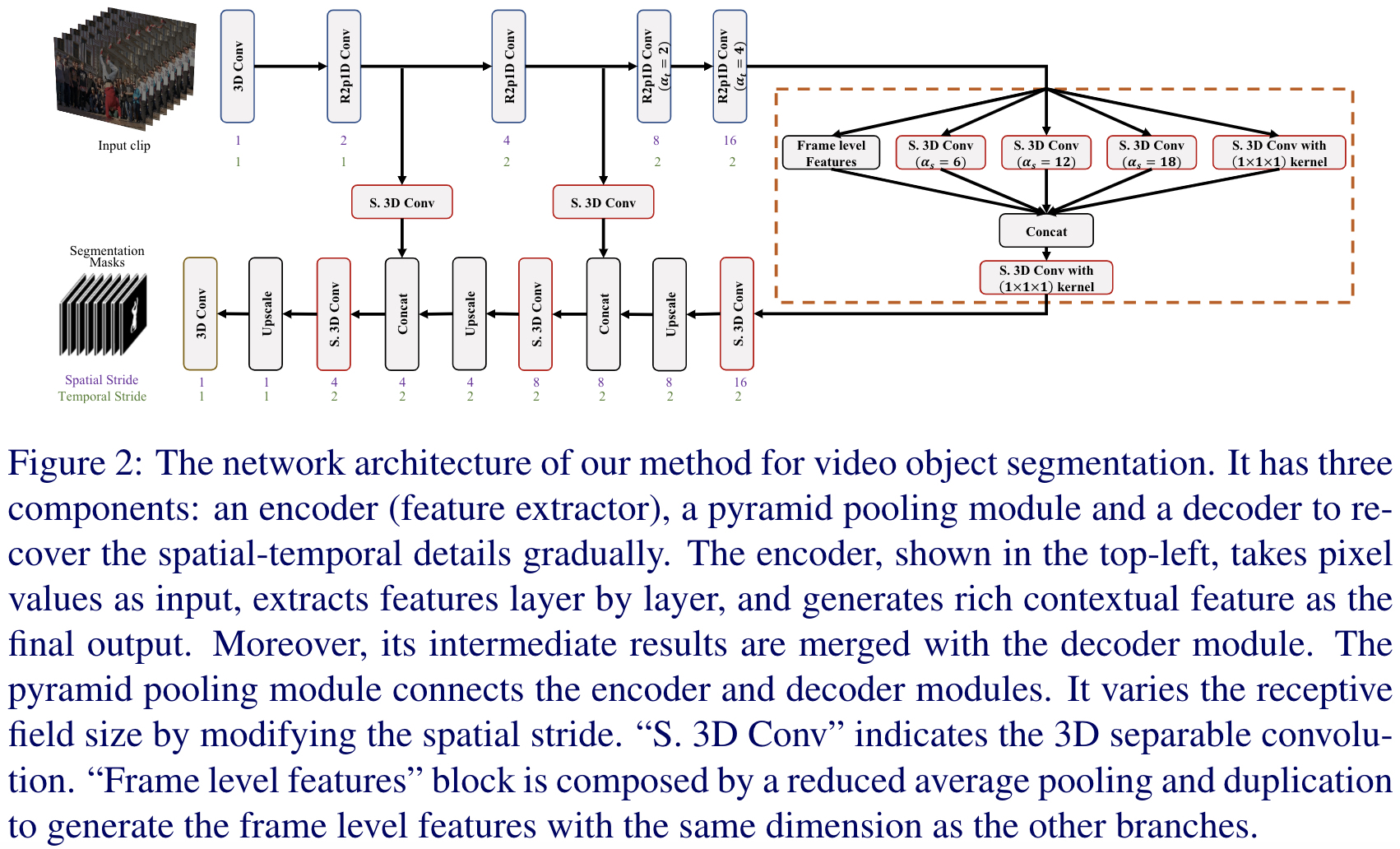
Results
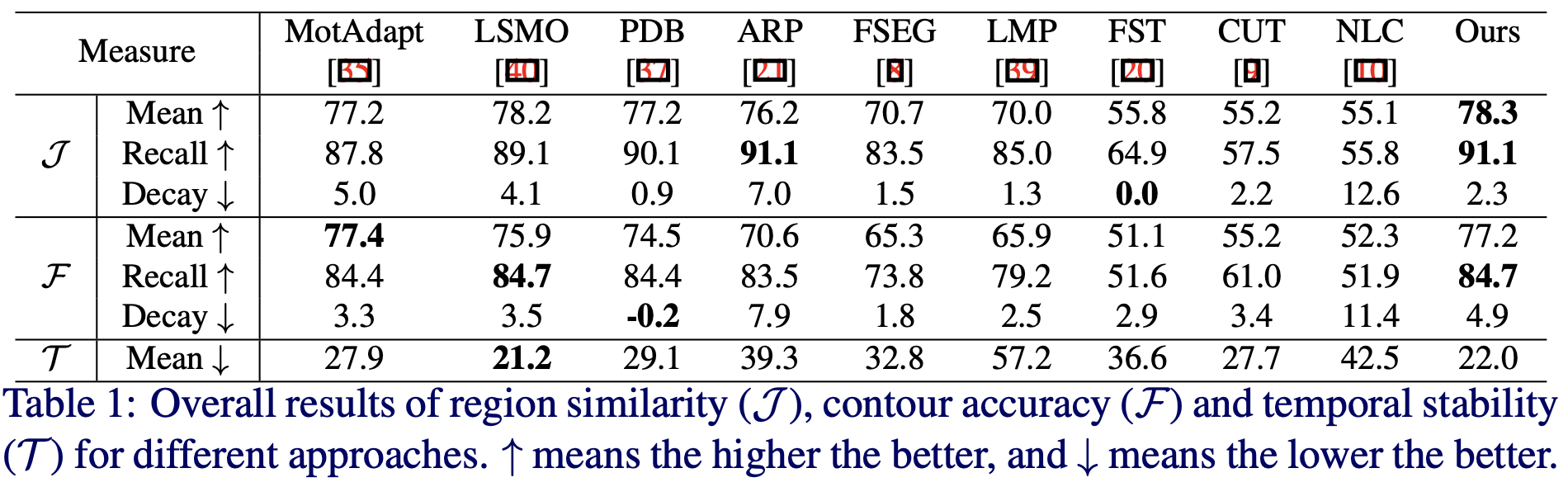
1. Video object segmentation results of the DAVIS'16 (Table 1) and Segtrack-v2 (Table 2) datasets


2. Example segmentation results of the proposed approach for a few testing video sequences from DAVIS dataset




3. Experiments on J-HMDB for action segmentation/detection

Publication
R. Hou, C. Chen, R. Sukthankar, and M. Shah, An Efficient 3D CNN for Action/Object
Segmentation in Video, the British Machine Vision Conference (BMVC), 2019.
2. Example segmentation results of the proposed approach for a few testing video sequences from DAVIS dataset
3. Experiments on J-HMDB for action segmentation/detection
Publication
R. Hou, C. Chen, R. Sukthankar, and M. Shah, An Efficient 3D CNN for Action/Object
Segmentation in Video, the British Machine Vision Conference (BMVC), 2019.
3. Experiments on J-HMDB for action segmentation/detection
Publication
R. Hou, C. Chen, R. Sukthankar, and M. Shah, An Efficient 3D CNN for Action/Object
Segmentation in Video, the British Machine Vision Conference (BMVC), 2019.