Research Projects
Research Sponsors
 |
Current Research Projects
NSF: CNS Core: UbiVision: Ubiquitous Machine Vision with Adaptive Wireless Networking and Edge Computing
(Funding Agency: NSF; Award #: 1910844; Amount: $419,794; PI: Tao Han, Co-PI: Chen Chen; 10/2019 - 09/2022)
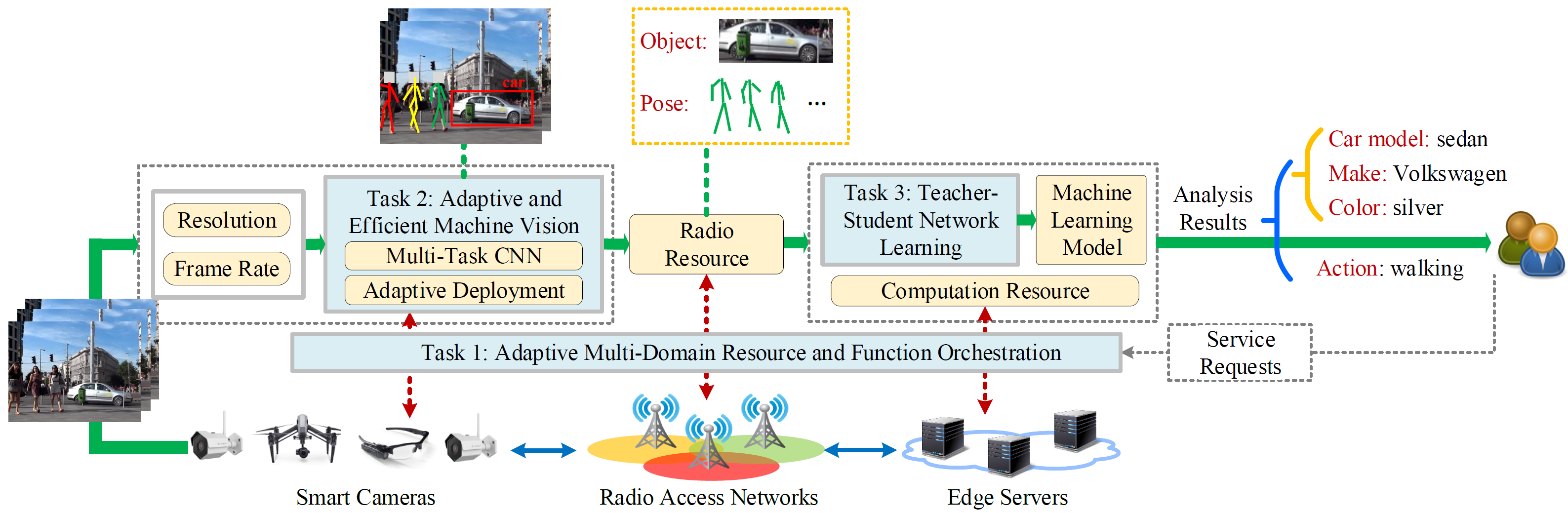 |
This project aims to realize an ambitious goal: ubiquitous machine vision (UbiVision) whose ultimate objective is to provide a platform that enables people from all over the world to share their smart cameras, which can be Uber, Airbnb, or Mobike in the context of smart cameras. For example, a person in New York City can “see” what is happening in Los Angeles via a wearable camera shared by another person located in Los Angeles. However, sharing the scenes captured by cameras directly will incur serious privacy issues. Moreover, the raw visual data may result in excessive traffic loads that congest the network and downgrade the system performance. To preserve privacy and reduce traffic loads, UbiVision performs visual data analysis on smart cameras and edge servers, which allows its customers to only share information extracted from camera scenes, e.g., how many people are queuing outside an Apple store for a new iPhone, or selected objects in the scene, e.g., a vagrant husky for the purpose of the lost and found. This project studies enabling technologies for realizing UbiVision. The UbiVision framework consists of three main research tasks. In this framework, smart cameras, radio access networks, and edge servers are recognized as infrastructure that can support multiple machine vision services through adaptive end-to-end multi-domain resource orchestration. The PIs envision that a machine vision service provider (MVSP) will own and manage a virtual network consisting of a radio access network and edge servers and have the access to ubiquitous cameras via camera sharing agreements with camera owners. Under this scenario, MVSPs are challenged to dynamically manage highly coupled resources and functions across multiple technology domains: 1) camera functions such as image preprocessing and embedded machine vision; 2) network resources in the radio access network; 3) computation resources and machine vision on the edge servers. To solve the problem, the PIs propose an interdisciplinary research project which integrates techniques and perspectives from wireless networking, computer vision, and edge computing in designing and optimizing UbiVision. Papers:
|
MLWiNS: Democratizing AI through Multi-Hop Federated Learning Over-the-Air
(Funding Agency: NSF & Intel Corporation; Award #: 2003198; Amount: $446,667 (NSF) + $223,333 (Intel); PI: Pu Wang, Co-PIs: Chen Chen, Minwoo Lee, Mohsen Dorodchi; 07/2020 - 06/2023)
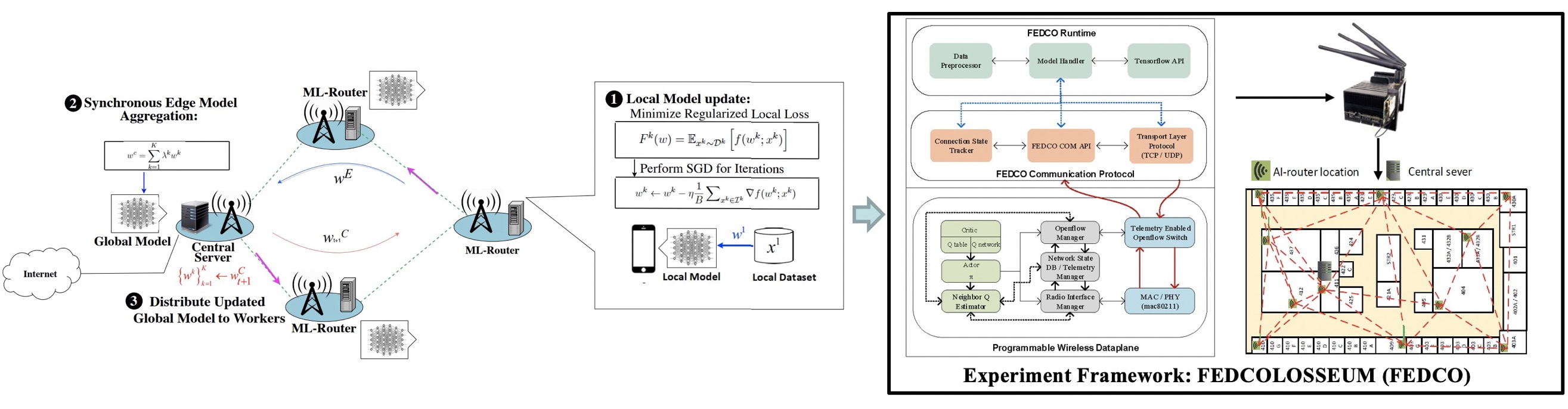 |
Federated learning (FL) has emerged as a key technology for enabling next-generation privacy-preserving AI at-scale, where a large number of edge devices, e.g., mobile phones, collaboratively learn a shared global model while keeping their data locally to prevent privacy leakage. Enabling FL over wireless multi-hop networks, such as wireless community mesh networks and wireless Internet over satellite constellations, not only can augment AI experiences for urban mobile users, but also can democratize AI and make it accessible in a low-cost manner to everyone, including people in low-income communities, rural areas, under-developed regions, and disaster areas. The overall objective of this project is to develop a novel wireless multi-hop FL system with guaranteed stability, high accuracy and fast convergence speed. This project is expected to advance the design of distributed deep learning (DL) systems, to promote the understanding of the strong synergy between distributed computing and distributed networking, and to bridge the gap between the theoretical foundations of distributed DL and its real-life applications. The project will also provide unique interdisciplinary training opportunities for graduate and undergraduate students through both research work and related courses that the PIs will develop and offer. Papers:
|
Cross-View Image Geo-localization
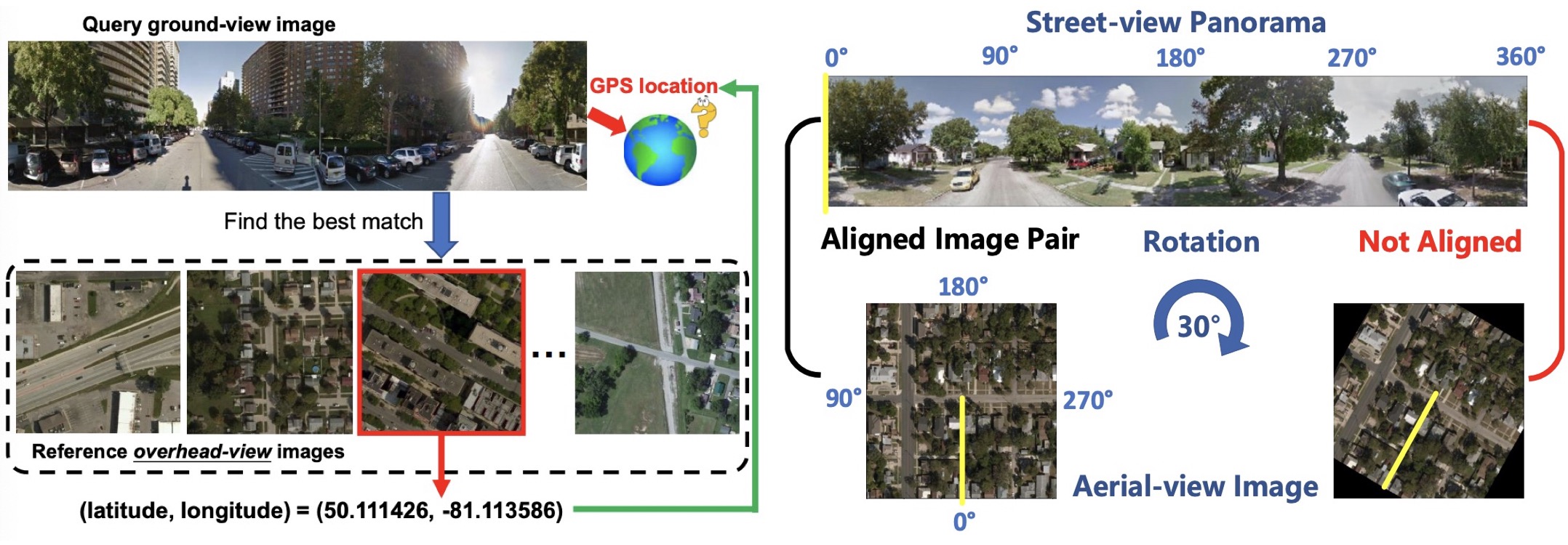 |
Cross-view image geo-localization aims to determine the locations of street-view query images by matching with GPS-tagged reference images from aerial view. In scenarios where GPS signal is noisy, image geo-localization can provide additional information to achieve fine-grained localization. Street-to-aerial geo-localization is also proved effective on city-scale street navigation. These practical applications make cross-view image geo-localization an important and attractive research problem in the computer vision community. Existing works assume 1) the alignment between street and aerial views is available and 2) each query ground-view image has one corresponding reference aerialview image whose center is exactly aligned at the location of the query image. However, in practice, these assumptions may not hold true. This project aims to study three problems: 1) how the alignment information would affect the retrieval model in terms of performance; 2) without assuming the inference image pairs are aligned, how to effectively improve the retrieval performance; 3) how to effectively perform geo-localization in a more realistic setting that breaks the one-to-one correspondence. Papers:
|
Human Motion Analysis (Action Recognition, Detection, Segmentation, and Prediction; 2D/3D Pose Estimation)
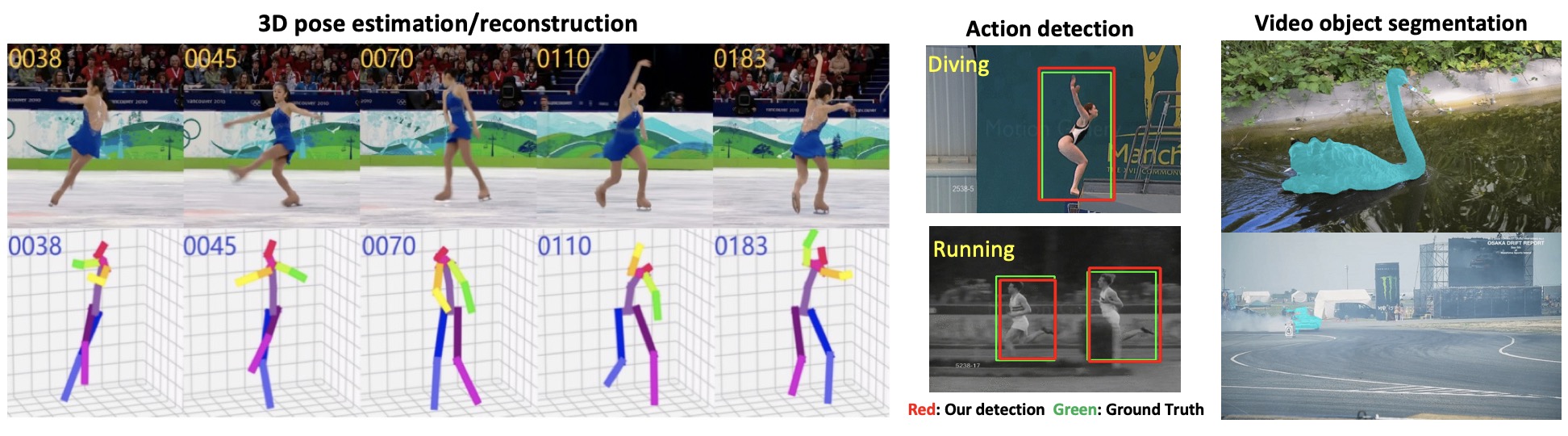 |
Visual analysis of human motion is one of the most active research topics in computer vision. This strong interest is driven by a wide spectrum of promising applications in many areas such as smart surveillance, human-computer interaction, augmented reality (AR), virtual reality (VR), etc. Human motion analysis concerns the detection, tracking and recognition of people, and more generally, the understanding of human behaviors, from sensor data (e.g., images, videos, etc.) involving humans. We aim to develop novel AI algorithms to analyze human motions from all the levels of actions, intentions and skills to study augmented human abilities. Papers:
|