
Mahalavanya Sriram, msriram2@uncc.edu
Chandan Mannem,cmannem@uncc.edu
Cloud Project Report
University Of North Carolina, Charlotte
In hundreds of various services, recommendation systems are used - from internet shopping to music to films, everywhere. We can see how these systems have a surprisingly large impact on the materials consumers engage with over the course of their daily lives. The purpose of the project is to create such recommendation framework for books. The method takes book reviews from the reader and seeks some books that the reader has not yet read but can rate exceptionally.
Problem Statement
The aim of this project is to develop the recommendation framework using Apache Spark on the choice of the user's book. In order to forecast those behaviors, recommendation systems use data models. For a given individual, the learned model can compute suggestions as well as compute comparable or similar items for a given object.
Data
The dataset contains ratings for ten thousand popular books (Goodbooks-10k). The size is about 40.59MB. Generally, there are 100 reviews for each book, although some have less - fewer - ratings. Ratings go from one to five. Both book IDs and user IDs are contiguous. For books, they are 1-10000, for users, 1-53424. All users have made at least two ratings. Median number of ratings per user is 8. to_read.csv provides IDs of the books marked "to read" by each user, as user_id, book_id pairs, sorted by time. There are close to a million pairs. books.csv has metadata for each book (goodreads IDs, authors, title, average rating, etc.). book_tags.csv contains tags/shelves/genres assigned by users to books. Tags in this file are represented by their IDs. They are sorted by goodreads book_id ascending and count descending.
Dataset URL
Context/Literature
For recommendation systems, there are three main approaches: (i) content-based, (ii) collaborative, and (iii) hybrid. Recommendation systems that implement a content-based (CB) approach generally recommend items to a user that are comparable to those previously preferred by the user. On the other hand, recommendation systems that implement collaborative filtering (CF) forecast the desires of users by observing user relationships and interdependencies between items; they extrapolate new associations from these. Finally, hybrid approaches incorporate content-based and collaborative approaches that have complementary strengths and disadvantages, delivering better outcomes.
Our Approach
Collaborative Filtering
In Collaborative filtering, we have used matrix factorizationmodel based algorithm.
Stochastic Gradient Descent
Collaborative filtering - Model based could generally strengthen the books recommendation framework. This is because in few cases it is necessary for certain number of interactions per item/user to deliver useful results. The model based recomendation systems are often more scalable beacuse the resultant from the model tend to be often much smaller than the actual dataset. Model-based systems are often likely to be quicker, at least compared to memory-based systems, since the time taken for the model to be queried (as opposed to the whole dataset) is typically much shorter than for the entire dataset to be queried. Matrix factorization is simply a family of mathematical operations for matrices in linear algebra. To be specific, a matrix factorization is a factorization of a matrix into a product of matrices. In the case of collaborative filtering, matrix factorization algorithms work by decomposing the user-item interaction matrix into the product of two lower dimensionality rectangular matrices. One matrix can be seen as the user matrix where rows represent users and columns are latent factors. The other matrix is the item matrix where rows are latent factors and columns represent items. Model learns to factorize rating matrix into user and book representations, which allows model to predict better personalized book ratings for users. With matrix factorization, less-known books can have rich latent representations as much as popular books have, which improves recommender’s ability to recommend less-known books Hence being a sparse dataset where the user participation is very less (i .e all user will not rate even when they have read a book), we have chosen a model based algorithm SGD. Stochastic Gradient is a method to minimize the error in the prediction. In an SGD based algorithmn the performance of the model is gradually increased. A main difference between Gradient descent and SDG is that, SGD averages multiple local losses rather than the exact loss at each step. In SGD a noisy gradient is calculated (i.e In GD, we have to run through ALL the samples in our training set to do a single update for a parameter in a particular iteration, in SGD, on the other hand, we use ONLY ONE of training sample from our training set to do the update for a parameter in a particular iteration). This makes the computation faster
Excecution Steps
- For this method, we read and merge book ratings (book id, user id,ratings ) and book (book id, title) files as data frames
- We have n users and m books. First, we create a ratings matrix m x n dimension and ratings as the values. Then we fill all the missing ratings with 0s.
- Then we split the matrix to train and test data. We roughly have removed values from the train set and placed it in the test set this is particularly because we hold few values of the user rating to the test set. Then we train the model with both the test and the train data.
- In the training method first we create two latent feature matrices. These matrices have a random value at the beginning. Then for each user book pair, we compute the error and update the latent feature matrix pair. Here the error calculation is based on simple subtraction between the values.
- The prediction is just the dot product of the two latent feature matrix.
- Calling Recommender class, which contains our main Stochastic Gradient Descent model that takes epochs, latent_feature, lambda, learning_rate as input parameters
- We finally obtain the matrix will all the predicted values. But in the predict method, we take only the unknown values as a return as rating prediction.
ALS - Alternating Least Square
A matrix factorization algorithm is also Alternating Least Square (ALS) and it operates in a parallel fashion. In Apache Spark ML, ALS is introduced and designed for larger-scale collaborative filtering problems. In solving the scalability and sparseness
of the rating data, ALS is doing a pretty good job, and it is easy and scales well to very large datasets
R = PQT
Where R is a Ratings Matrix, P and Q are features matrices of
users and items Alternating Least Squares can solve for pu and qi in alternate iterations each time by assuming the other value is known.
Now, we can estimate the unknown rating values by
r
ui = puqi T
In our implementation we have used the Spark ML lib for our implementation. ALS uses L2 regularization. ALS minimizes two loss functions alternatively; It first holds user matrix fixed and runs gradient descent with item matrix; then it holds item matrix fixed and runs gradient descent with user matrix. ALS runs its gradient descent in parallel across multiple partitions of the underlying training data from a cluster of machines.
Most important hyper-params in Alternating Least Square (ALS):- maxIter: the maximum number of iterations to run (defaults to 10)
- rank: the number of latent factors in the model (defaults to 10)
- regParam: the regularization parameter in ALS (defaults to 1.0)
- In our implementation, iterations are 10 and the rank is 5
Excecution Steps
- For this method, we read data
- We then in distributed manner extracted the user_id, ratings, book_id
- We then split the data to train and test
- We then passed the data to the ALS function
- Defining Loss RMSE as our loss function
- Finally predicting the ratings in our test set
Content based Filtering
Content-based recommendation systems recommend items to a user by using the similarity of items. This recommender system recommends products or items based on their description or features. It identifies the similarity between the products based on their descriptions. It also considers the user's previous history in order to recommend a similar product.
Example: If a user likes the novel “Tell Me Your Dreams” by Sidney Sheldon, then the recommender system recommends the user to read other Sidney Sheldon novels, or it recommends a novel with the genre “non-fiction”. (Sidney Sheldon novels belong to the non-fiction genre).
Excecution Steps
- Below Data files are needed to execute our Model:
- book.csv( book_id, title)
- tags.csv( tag_id, tag_name )
- book_tags.csv( goodread_book_id, tag_id )
- ratings.csv( book_id, user_id, rating )
- We load above csv files into our data frames. First we merge book_tags and tags based on tag_id.
- we merge the output dataframe with books based on book_id
- inally we drop all the columns except book_id, title and tag_name
- We then converted tags into individual tokens by calling tokenize method.
- We describe 'featurize' method, which is the key intuition behind the implementation of the content based implementation, and takes books file for features called 'features' as input and inserted column.
- A csr matrix of type (1, num features) is included in each row of our book data frame.
- We created a csr matrix by using features in books data frame.
- Then we randomly sampled our data for training and testing.
- hen we calculated cosine similarity which take the 2 vectors and measures the angle between them.
- And finally, our 'make_predictions' method returning one predicted rating for each element of ratings_test.
Task Involved
- Literature Survey
- Dataset collection
- Data cleaning and pre-processing
- Data visualization
- Algorithm selection
- Designing Recommender Architecture
- Implementation of the algorithms
- Quantitative analysis of the results
Results
SGD Exsisting Ratings
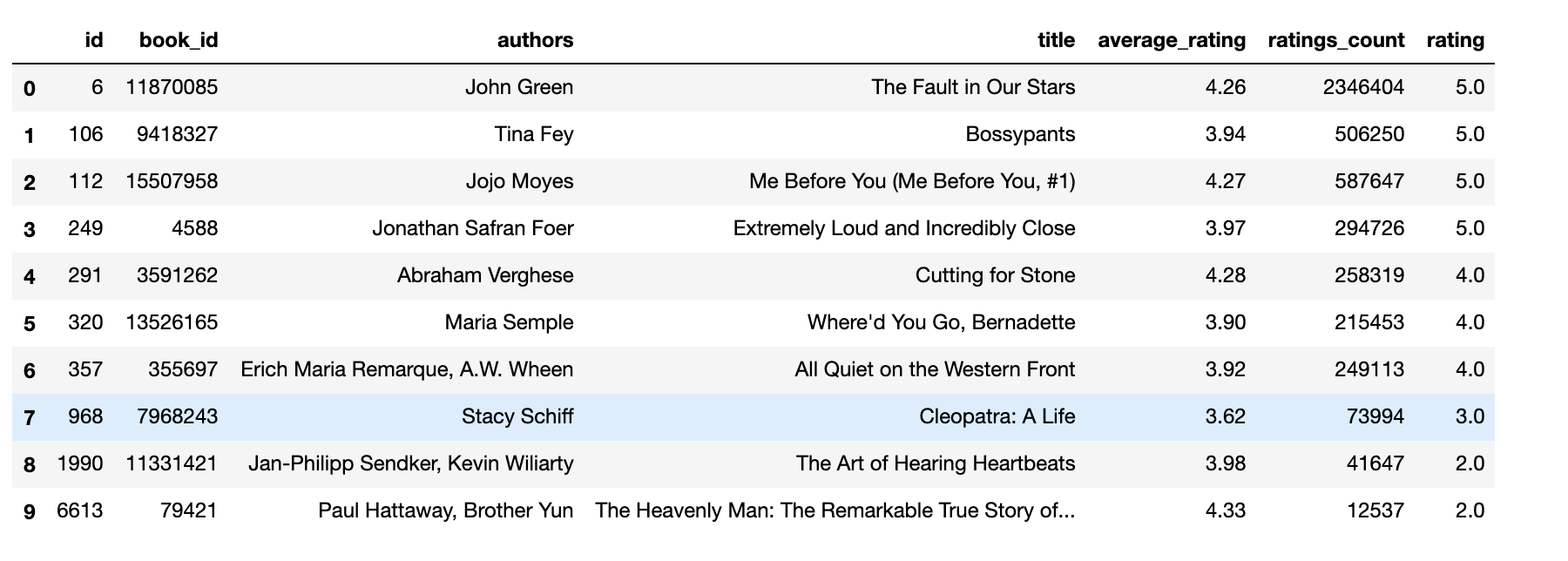
SGD Predicted Ratings
 Regarding the result, after a detailed analysis of each book on the internet we have found out that the genre of all the books belongs to fiction.
Though they are different types of fiction they have a similar prediction. we have given below a few example genres from google
Regarding the result, after a detailed analysis of each book on the internet we have found out that the genre of all the books belongs to fiction.
Though they are different types of fiction they have a similar prediction. we have given below a few example genres from google
-
Existing
Books - Genres
- The Fault in Our Stars - Novel, Young adult fiction, Romance novel
- Me Before You (Me Before You, #1) - Romance novel, Fiction
- Extremely Loud and Incredibly Close - Novel, Fiction
- Wonder - Fiction, Novel, Children's literature
- Cutting for Stone - Novel, Domestic Fiction
-
Predicted
Books - Genres
- The Hunger Games (The Hunger Games, #1) - Novel, Science Fiction, Children's literature
- Harry Potter and the Sorcerer's Stone - Novel, Children's literature, Fantasy Fiction, High fantasy
- The Kite Runner - Novel, Bildungsroman, Drama, Historical Fiction
- Harry Potter and the Deathly Hallows - Novel, Children's literature, Bildungsroman, Mystery, Thriller, Young Adult Fiction, Fantasy Fiction, adventure fiction, Thriller
- A Wrinkle in Time - Novel, Young adult fiction, Science Fiction, Children's literature, Fantasy Fiction, High fantasy, Science fantasy
- The Emperor's Soul - Fantasy, Fiction, Novella
Content Based Prediction

Content Based Error
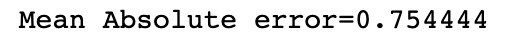
ALS Results
Prediction for user id = 455689 (455689, (Rating(user=455689, product=79978839, rating=9.28312605691584), Rating(user=455689, product=63029048, rating=9.140859529248129), Rating(user=455689, product=60479815, rating=8.955454355150538), Rating(user=455689, product=76461737, rating=8.798472519872886), Rating(user=455689, product=75081857, rating=8.715562597090958), Rating(user=455689, product=31352695, rating=8.603800595453881), Rating(user=455689, product=12806744, rating=8.521654624741522), Rating(user=455689, product=26731247, rating=8.44251364425917), Rating(user=455689, product=78900662, rating=8.21295918611597), Rating(user=455689, product=91873667, rating=8.183359998682398))
| Error | MSE | RMSE |
|---|---|---|
| Train | 0.6289847833482564 | 0.7930856090916392 |
| Test | 1.0536923095065984 | 1.026495158053168 |
Tools Used
- Apache Spark
- Python 3.7
- Java 1.8
- Jupyter Notebook
- UNCC-DSBA cluster/ AWS EMR cluster
Things Learnt
- Implementation of collaborative filtering using Stochastic Gradient Descent algorithm.
- Implementation Content based filtering using cosine similarity and TF-IDF vector.
- The complexity and challenges of pre-processing huge datasets and modeling the data suitably.
- During our literature survey, we learned different approaches to implement recommender systems.
- We also learned the sprak implementation
- This project gave us a clear understanding of how to select datasets, what to look for in them and manipulate them to derive usable insights.
Task Division
| S.no | Task | Member |
|---|---|---|
| 1. | Literature Survey | Both |
| 1. | Literature Survey | Both |
| 2. | Problem Identification and Dataset Collection | Both |
| 3. | Data Cleaning and Preprocessing | Both |
| 4. | Content filtering | Chandan Mannem |
| 5. | collaborative filtering - SGD | Mahalavanya Sriram |
| 6. | Content Based and ALS in spark | Both |
| 7. | Experiments, Result Analysis, and Final Report | Both |
Challenges
- Understanding the mathematical formulas, derivations and principles behind content-based and collaborative filtering was difficult.
- At one point, we were quite uncertain about the latent features used in the ALS algorithm.
- The learning curve to translate our understanding of TF-IDF vectorization and cosine similarity that are applied on bag of words to work for book recomendation was overwhelming, but we overcame it eventually.
- Large data sets that we use for books recommendations have led us to a lot of problems related to efficiency.
- We tried to implement our model in pyspark. We almost implemented the model but we are getting errors saying spicy libraries. We digged into that issue and found out that the libraries that we installed are in master node but worker nodes not able to install those libraries.
- We implemented ALS methods in pyspark. It was so difficult to implement the in pyspark but we are finally able to do it.
Conclusion
Recommendation systems are very common these days and can be seen in most of the digital platforms that we use every day. Some of the most observed examples where recommendation systems play a vital part would be in e-commerce website like Amazon and streaming applications like Netflix and YouTube. The need for recommendation systems are due to the growing demand in competition , increase customer base and satisfaction. In our project we have described and developed the Collaborative and Content based filtering to determine the user pattern. We also achieved data parallelization using Spark where we made use of the RDD data structure and effectively modelled the output.
Credits: uncc.edu