Introduction
Data Mining
Data Mining refers to extracting or mining knowledge from large amounts of data. Data mining is an essential step in the process of knowledge discovery in databases. Knowledge discovery as a process consists of an iterative sequence of the following steps:
- Data Cleaning ( to remove noise and inconsistent data)
- Data Integration ( where multiple data sources may be combined)
- Data Selection (where data relevant to the analysis task are retrieved from the database)
- Data Transformation( where data are transformed or consolidated into forms appropriate for mining by performing summary or aggregation operations)
- Data Mining ( an essential process where intelligent methods are applied in order to extract data patterns)
- Pattern evaluation ( to identify the truly interesting patterns representing knowledge based on some interesting measures)
- Knowledge presentation ( where visualization and knowledge representing knowledge based on some interesting measures)
Data Mining Functionalities
In general, data mining tasks can be classified into two categories: descriptive and predictive. Descriptive mining tasks characterize the general properties of the data in the database. Predictive mining tasks perform inference on the current data in order to make predictions.
It is important to have a data mining system that can mine multiple kinds of patterns to accommodate different user expectations or applications. Furthermore, data mining systems should be able to discover patterns at various granularities. Data mining systems should also allow users to specify hints to guide or focus the search for interesting patterns.
Some of the Data mining functionalities are defined below.
Data Characterization is a summarization of the general characteristics or features of a target class of data. The data corresponding to the user specified class are typically collected by a database query.
Data Discrimination is a comparison of the general features of target class data objects with general features of objects from one or a set of contrasting classes. The target and the contrasting classes can be specified by the user, and the corresponding data objects retrieved through database queries.
Associative analysis is the discovery of association rules showing attribute value conditions that occur frequently together in a given set of data.
Classification is the process of finding a set of models (or functions) that describe and distinguish data classes or concepts, for the purpose of being able to use the model to predict the class of objects whose class label is unknown. The derived model is based n the analysis of a set of training data. The derived model may be represented in various forms, such as classification rules, decision trees, mathematical formulae or neural networks. Classification can be used for predicting the class label of data of objects. However, in many applications, users may wish to predict some missing or unavailable data values rather than class labels. This is usually the case when the predicted values rather are numerical data and is often specially referred to as a prediction.
Unlike classification and prediction, which analyze class labeled data objects, clustering analyzes data objects without consulting a known class label.
Proposal
The goal of the project is to apply trend analysis to time series stock data of a particular company in order to predict the movement of the stock.
The stock data for Bank of America has been chosen. The dataset is continuous valued. It contains the average values of the stock over a certain period of time.
Prediction has been used for data analysis to predict the future data trends of stock. The data tuples are analyzed, the training data set, is selected from the sample data set. This learned model is represented in the form of association rules. This step is the supervised learning step. Hold out method is then used wherein a test set of class labeled samples are selected and these are independent of the training samples. The accuracy of a model on a given test is the percentage of test samples that are correctly classified by the model. For each test sample, the known class label is compared with the learned model’s class prediction for that sample.
After this accuracy of the model is considered acceptable, the model can then be used to classify future data.
Associative rule mining helps in finding interesting association relationships among large set of data items. The discovery of such associations can help develop strategies to predict. Hence association rule mining has been used for the project.
Data Preparation
The data has been collected for Bank of America for a period of ten years, from 1992 to 2002, from the internet website (http://finance.yahoo.com) and imported into Microsoft Excel spread sheets.
The data collected was the open, low, high and closing stock price for the particular day. The data size is about 2500 records.
Data Cleaning
Not much data cleaning was
required. Missing data was replaced by the correct one obtained from the
internet. The data was searched for any steep changes in it which might have
occurred by stock splits etc., but did not find any.
Data Transformation
The attributes used for the
analysis are the Two-day average, Five-day average, Ten-day average, Volume,
Average True Range (ATR), and Absolute Price Oscillator (APO) with the Closing
stock price as the decision attribute. The indicators ATR and
- Multiply
the previous 14-day ATR by 13.
- Add the
most recent day's TR value.
- Divide by
14.
Absolute Price Oscillator (APO) is an indicator based on the difference between two moving averages, expressed as either a percentage or in absolute terms. It is calculated using the formula
where EMA, Exponential Moving Average, is calculated by:
EMA = (K* (C-P) + P)
where K = 2/ (Time periods +1),
C= current closed price
P= previous EMA
The data has been calculated using the mathematical formulae and connected to the existing spread sheet.
The data has been transformed into percentages, wherein the percentages are obtained according to the increase or decrease with respect to the previous day.
Data Reduction
The final data was planned to have closing price as decision
attribute with 2-day, 5-day, 10-day averages followed by
Data Generalization
The decision attribute was generalized to 0’s and 1’s according the increase or decrease of the close stock price compared to its previous day price. Here 1 shows that the there was an increase in the value and 0 shows a decrease when compared to the corresponding previous day value.
Data Discretization
The data has been discretized using the software ROSETTA. The Equal frequency Binning algorithm has been used for the discretization. The binning methods smooth a sorted data by consulting the values around it. The sorted values are distributed into a number of buckets or bins. Here the number of bins used is ten. The data is discretized and put into bins. Each bin was given a separate name for the purpose of increasing the ease of understanding when the rules are developed.
The discretized data was spilt in to training data and test data. Then the training data was converted to a format (Decision Table) suitable to Data mining Tool “LERS” which builds association rules. This table when submitted to LERS, provided a consistency 99.79%.
Associative Rule
Mining
The input file of 1000 records was fed to LERS system to generate association rules. A total of 1059 rules were obtained, out of which 532 were certain rules and 527 were possible rules.
Support and confidence for all the rules were calculated manually (using SQL). A threshold support value was chosen to obtain minimum number of rules to predict. This threshold support value was used to filter the rules. This filtration process was done manually. The total number of rules obtained after the filtration process were 55 out of which 27 were certain rules and 28 were possible rules having a support value greater than 0.5.
These rules were applied to the test data to predict the decision value, closing stock price. Only 150 records could be used as test data, the reason being; only these records could satisfy the combination of attribute values matching the rule set.
These records were fed manually into the LERS system to predict the accuracy. The accuracy rate was found to be 51.33%
The results are as follows:
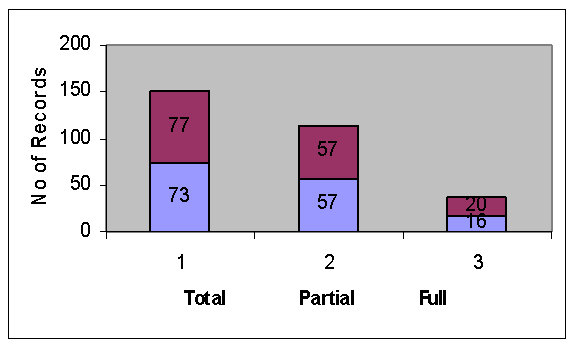
No. of Records in the Test Data Set = 150
Total No. of correct matches Found = 77
Accuracy = 51.33%
No. of correct Full matches = 20 out of 36
Accuracy =
55.55%
No. of correct Partial matches* = 57 out of 114
Accuracy =
50%
* Partial matches are those matches that fully do not match
the information that has been entered but which are close. Here Less one pair was selected which
enabled the system to match the rules even if one condition was not satisfied
while the others did.
Graphical
Representations of the Results
Experiences and
Challenges
- A proper manual for LERS was not available in the beginning.
- The LERS system available could not accept huge data sets.
- The LERS system does not facilitate the support and confidence measures, hence, manual methods were used which was tedious and time consuming.
- The less accuracy obtained might be due to the insufficient information on the dataset, hence a bad attribute selection.
- The LERS system did not facilitate any filtering process, hence manual methods were used which was tedious and time consuming.
Distribution of work
Most of the work was done as a team. The manual process was divided into three parts and was worked on.
Collection and processing of Data: Sudhir K V Potturi
Discretization and Data mining: Deepathi Lingala
Data Mining and Documentation: Sathindra K Kamepalli
Calculating of support and confidence: Sudhir, Deepathi, Sathindra
Applying rules to test Data: Sudhir, Deepathi, Sathindra
Appendices
Appendix A Original Data set (OrgDataset.xls)
Appendix B Processed Data ser (ProDataset.xls)
Appendix C Original Rule File (orgrule.txt)
Appendix D Filtered Rule File (filrule.txt)
Appendix E Test Data set (TestDataset.xls)
Appendix F Training Data set (TrainDataset.xls)