Lately I have been enjoying messing around with AI image generation. It is pretty easy to get started using AI image generators with the likes of Open AI's Dalle and Stability AI's Stable Diffusion. Some of those options are as follows:
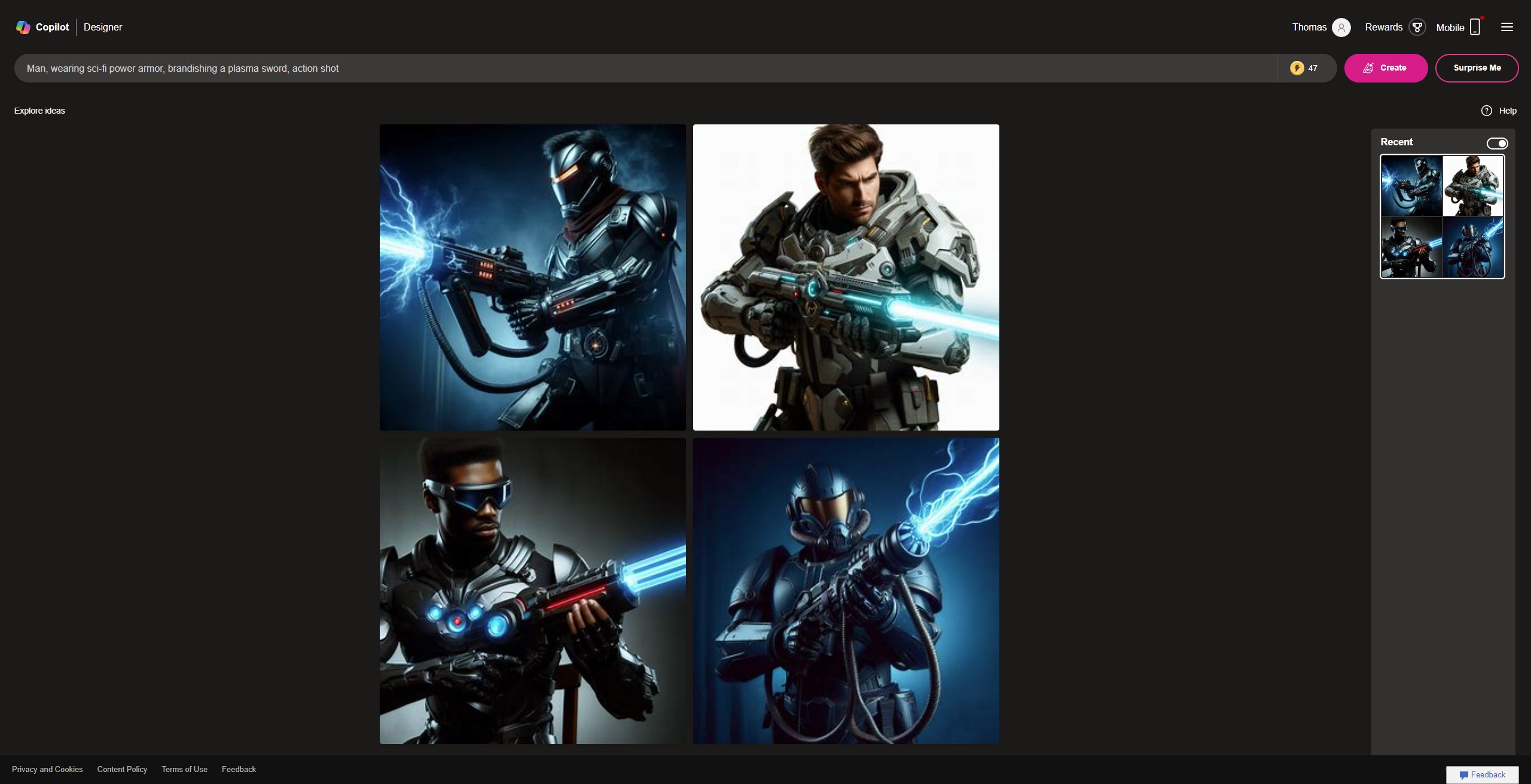
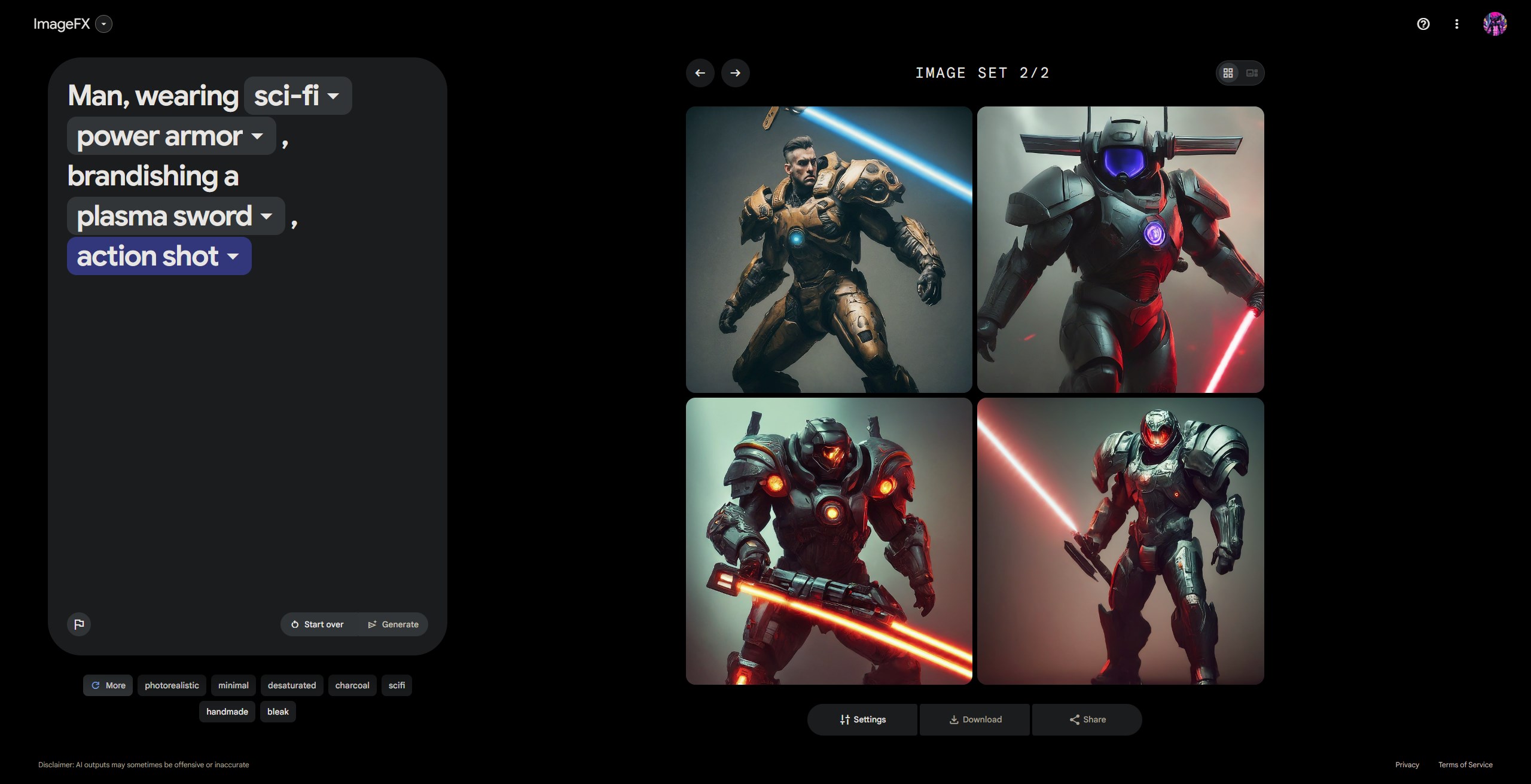
Prompt:Man, wearing sci-fi power armor, brandishing a plasma sword, action shot
Copilot Designer generating images based on the prompt
ImageFX generating images based on the prompt
Running image generation yourself locally
If you want to generate images without using an online provider you can. While it isn't as simple as using an online service it is still quite doable.
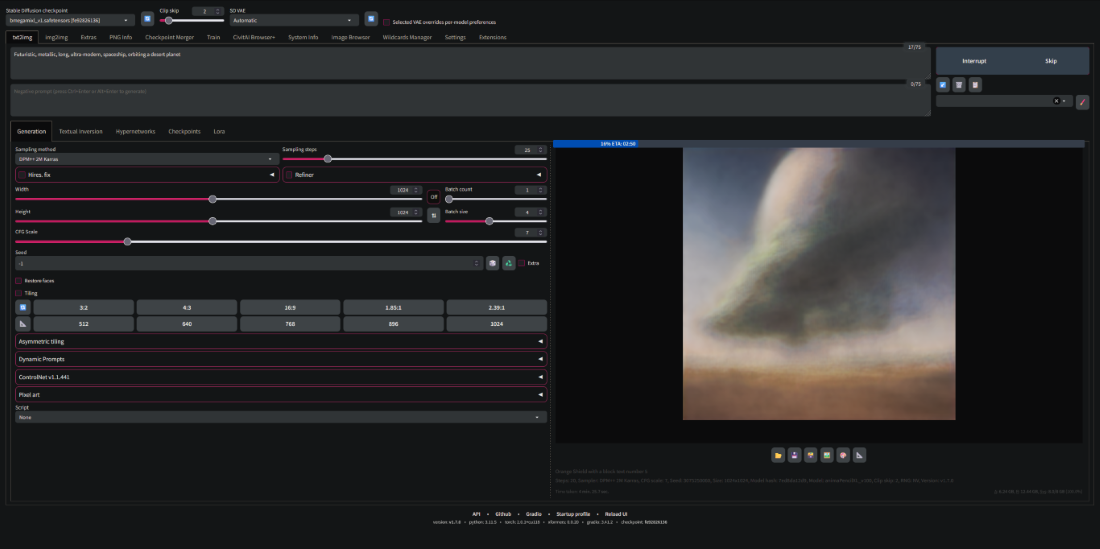
There are several different tools to use for generating your own images locally through webuis. The most popular is Stable Diffusion Web UI by Automatic1111 which has a simpler to use UI that is extensible.
Automatic1111 Web UI example
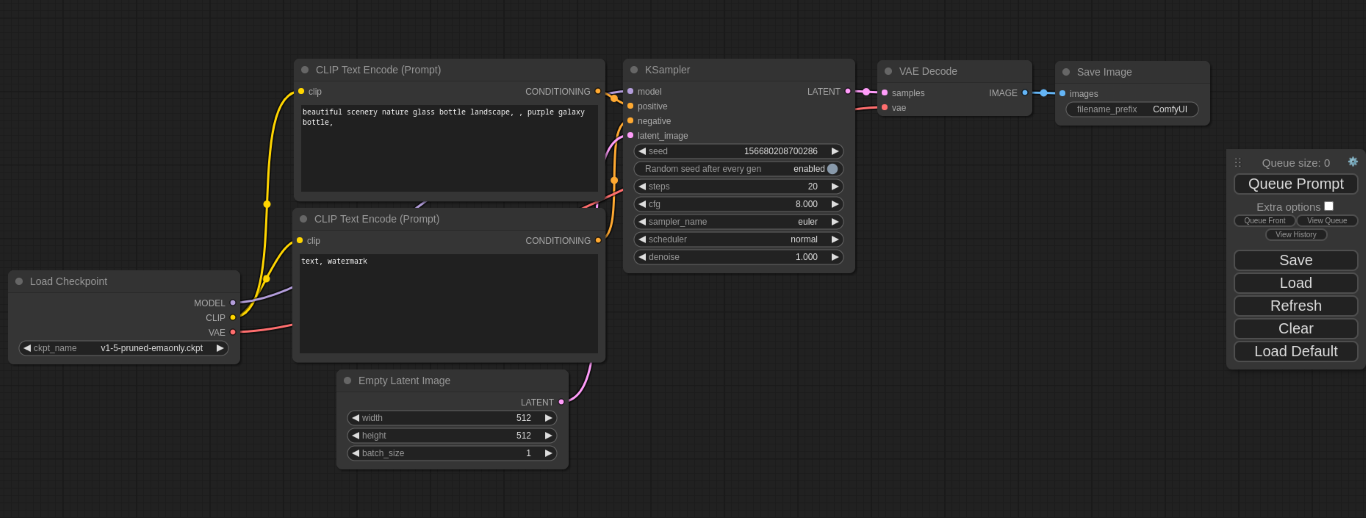
For a more complex and customizable webui there is Comfy UI which is a node based image generation ui that allows complex workflows to be easily visualized
Comfy UI example
Both of these options allow you to either install with portable install files, or cloning their git repos, and are built with python. I believe both come with the basic stable diffusion model prepackaged, but if not just download it and stick them in the model folder specified by your pick and get started.
Advanced Uses
After you get your prefered stable diffusion Web UI set up there are tons of options you can tweak, and additional models and tools you can use to enhance your generated images.
Different models
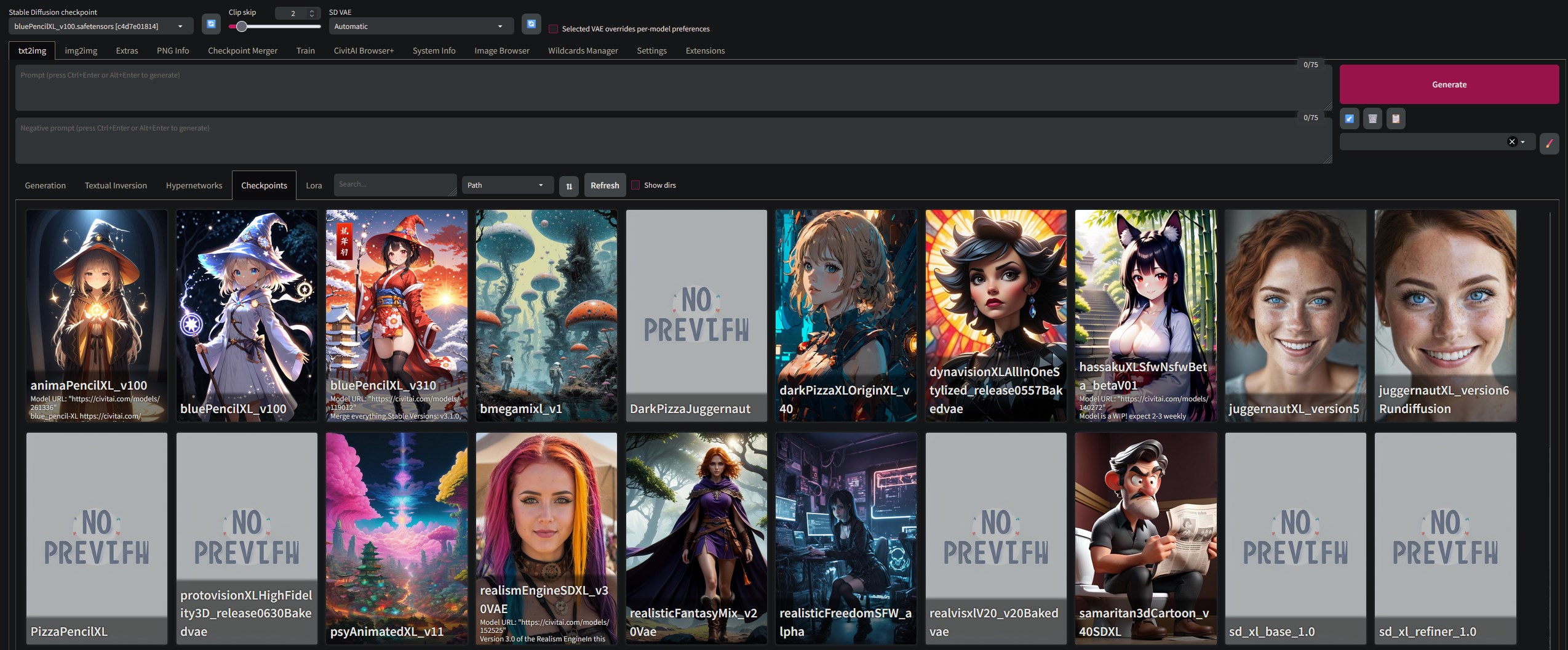
If you feel like the basic Stable Diffusion, or the XL version aren't enough websites like CivitAI provide user trained models that are trained on images in different styles, pick and choose finding models that are to your liking.
Checpoints tab in Automatic1111
If you find two checkpoints that you like and want to combine that is possible to do within the webui on the checkpoint merger tab.
Textual Inversion
Textual inversions are prepackaged terms aka tokens that can be used to get more specific details out of a generic prompt. You can find these on CivitAI as well. Most of the textual inversions I use come from this pack.
LoRA & LyCORIS
LoRA and LyCORIS are similar to textual inversion in that they are meant to tweak the final output of a models generated image, but different in how they operate. These are small models trained off of images in a specific style and can be triggered off of specific words in a prompt. These models can also be specifically activated, if you don't want to use their keywords in a prompt. Weights can also be applied to LoRA and LyCORIS models if you want the effects to be stronger or weaker in a final image.
Automatic1111 Prompt Extensions
The Web UI that I primarily use is Automatic1111, many users have made extensions that can be added to extend functionality. Below I'll talk about some of the different extensions that I use.
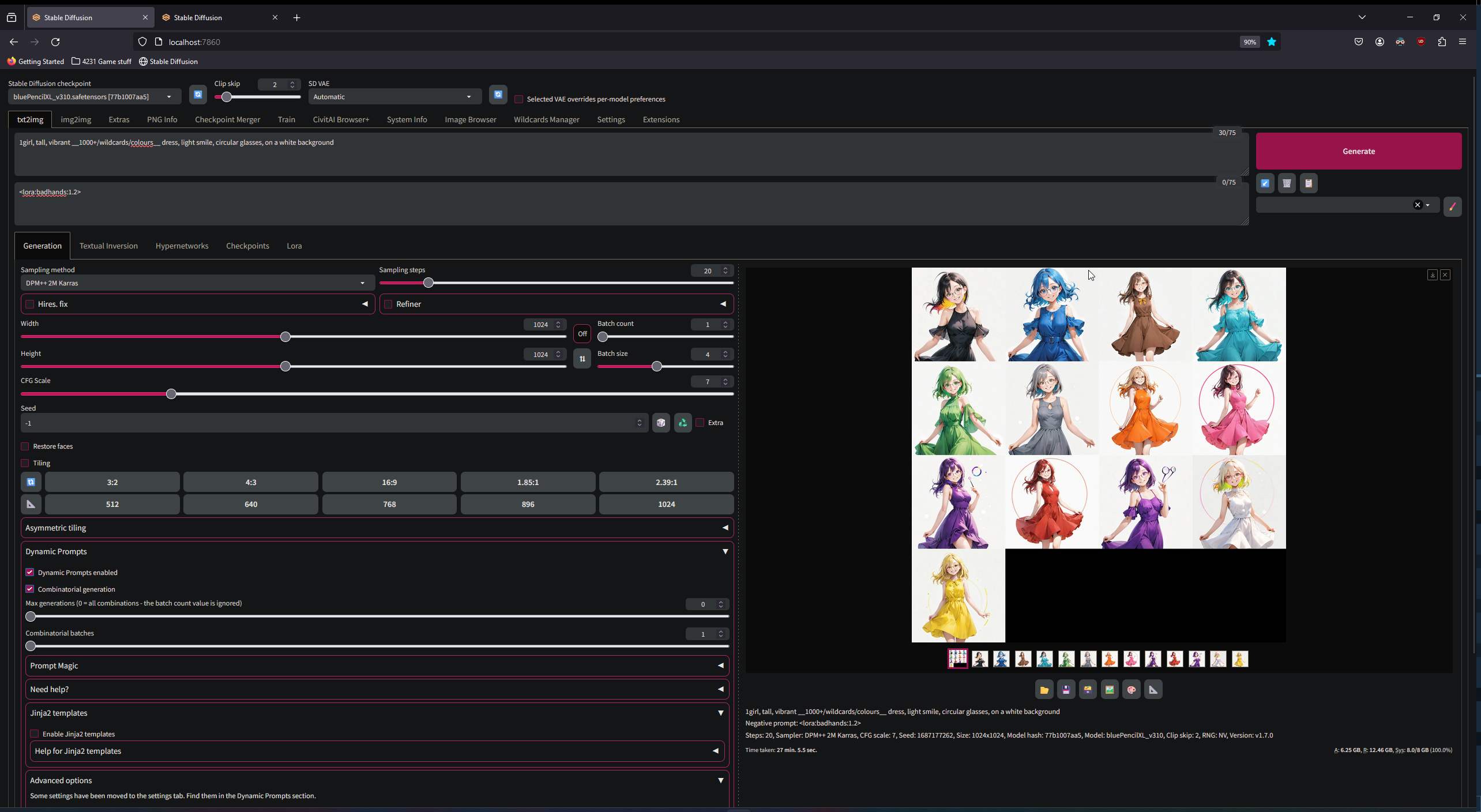
Some of my most used extensions are for prompting, specifically tag complete and dynamic prompts. Tag complete allows you to auto complete terms and change them out with tags from danbooru, a training datasets caption agregator, that allows for more consistent image generation. Dynamic prompts is a more extensive tool than the built in scripts allowing for more randomized generations or iterations over various terms from lists called wildcards. The specific dynamic prompt extension can also use chatgpt like large language models to improve uppon your own prompt to generate more interesting or detailed images
How to use Dynamic Prompts to generate images using wildcards












































{kind=link}