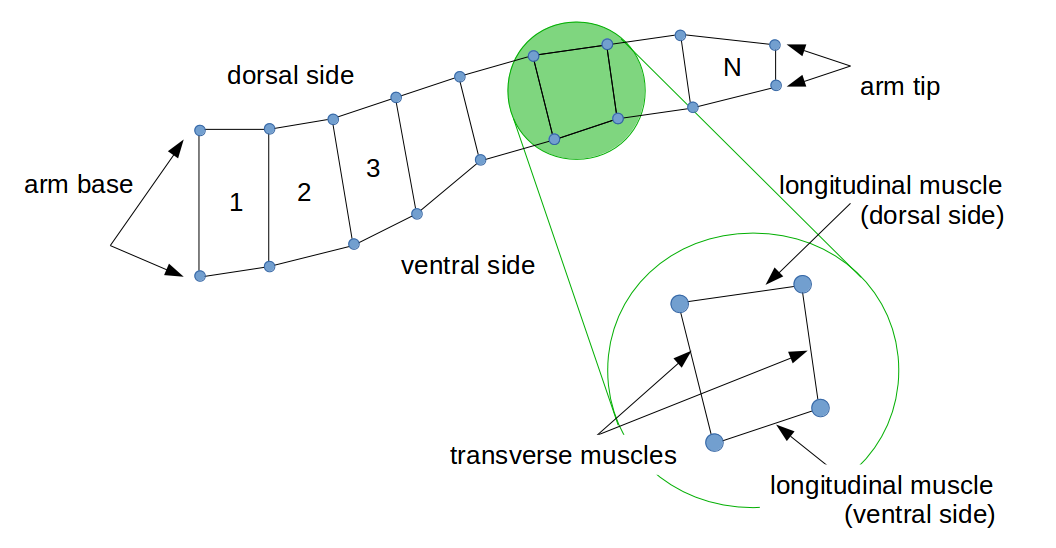
Octopus arm problem is for learning to control the simulated octopus arm through viscous environment to achieve a certain goal.
By controlling each muscle in individual compartment, the agent moves the tip of the arm close to the goal.
This is very interesting problem because of its high-dimensional actions, non-linear dynamics, and large search space.
Method:
Our recent approach uses relevance vector machine to sample continuous actions from relevance vectors.
As learning progresses, relevance vector sampling discovers continuous actions that maximize the estimated Q values. Following videos display the success learning the curling action.
After training for 10 episodes
After training for 35 episodes
After training for 70 episodes
After training for 100 episodes
After training for 150 episodes
Learned Policy
Alternating Goals on Each Episode: Touching the object with any part of trunk
The learning curve below shows the sum of rewards for each episode during training an agent.
For training to handle changing goals, the goal is changed to above the arm and under the arm and the goal location is given as an input.
The agent gradually learns the policy that can reach the different goal.
The triangles are the position where the learned trajectories are sampled for the following animations.
After training for 10 episodes
After training for 11 episodes
After training for 24 episodes
After training for 25 episodes
After training for 50 episodes
After training for 51 episodes
After training for 150 episodes
After training for 151 episodes