ITCS 4101: Introduction to Natural Language Processing
Spring 2026
Time and Location: Tue, Thu 2:30 – 3:45pm, Duke 207
| Instructor & IAs: |
|
Razvan Bunescu |
|
Andrew Morgan |
|
Kento Hopkins |
| Office: |
|
Woodward 410G |
|
Cone 164 |
|
Cone 164 |
| Office hours: |
|
Tue, Thu 4:00 – 5:00pm |
|
Mon 3:00 – 4:00pm |
|
Wed 11:00am – 12:00pm |
| Email: |
|
rbunescu @ charlotte edu |
|
amorga94 @ charlotte edu |
|
khopki22 @ charlotte edu |
Textbook (PDF available online):
Speech and Language Processing (3rd edition draft), by Daniel Juraksfy and James E. Martin; draft released on Jan 6, 2026.
Course description:
Natural Language Processing (NLP) is a branch of Artificial Intelligence whose focus is on the development of computer systems that process or generate natural language. This course will first introduce fundamental linguistic analysis tasks, including tokenization, syntactic parsing, semantic parsing, and coreference resolution. We will then study vector based representations of text, ranging from bag-of-words and TF-IDF to neural word and text embeddings. The course will survey machine learning models and techniques underlying modern NLP, including attention and Transformer-based language models, which will be used in a number of NLP applications such as sentiment classification, information extraction, or question answering. In parallel, the course will introduce standard frameworks for developing workflows where LLM-based agents connect with tools and communicate with other agents. Overall, the aim of this course is to equip students with an array techniques and tools that they can use to solve known NLP tasks, as well as new types of NLP problems.
Prerequisites:
Introduction to Machine Learning (ITCS 3156). Students are expected to be comfortable with programming in Python, data structures and algorithms (ITSC 2214), and basic machine learning techniques. Relevant background material will be made available on this website throughout the course.
Lecture notes:
- Syllabus & Introduction
- Python for programming, linear algebra, and visualization
- Tokenization: From text to sentences and tokens
- Regular expressions
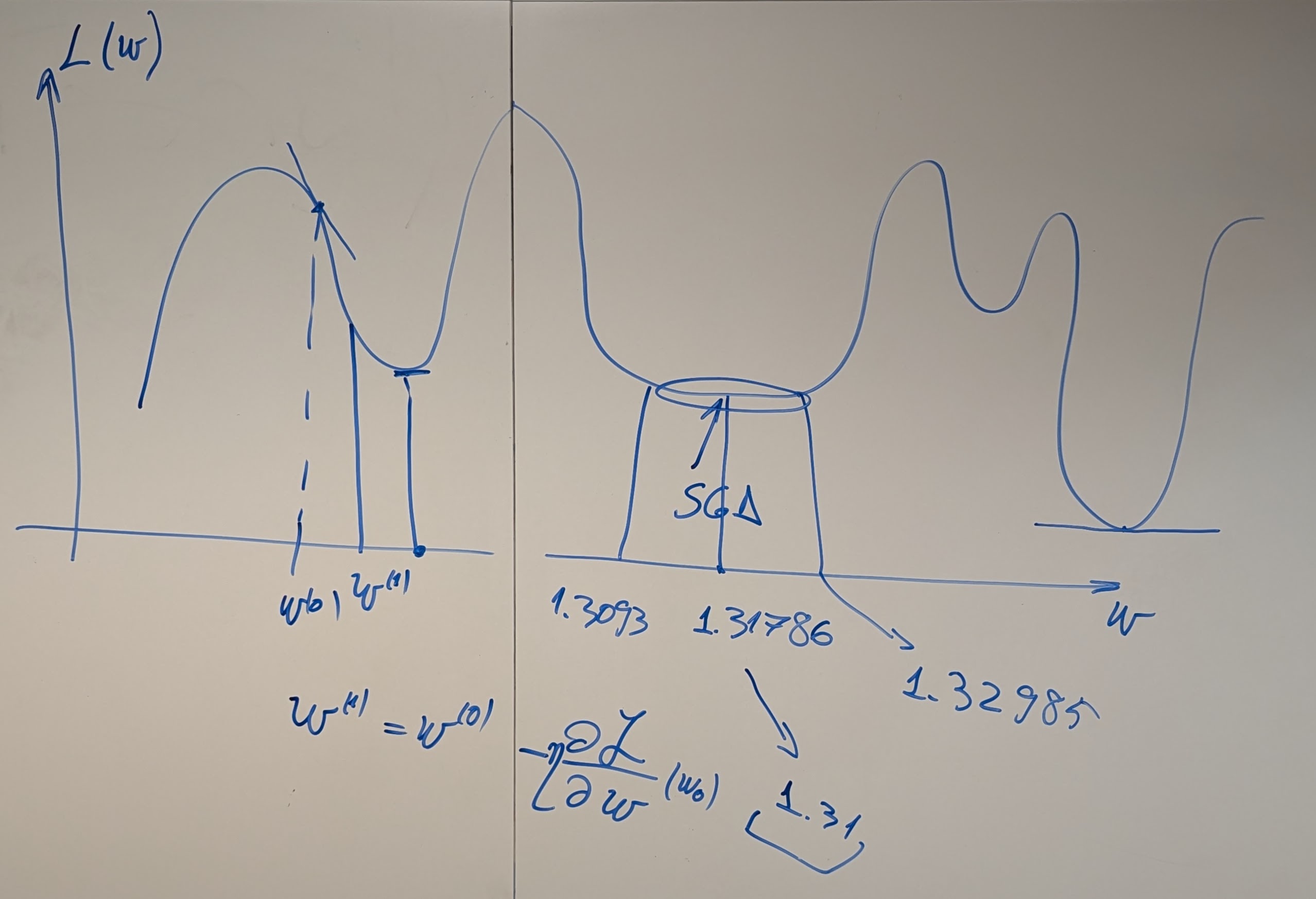
- Text classification using Logistic Regression
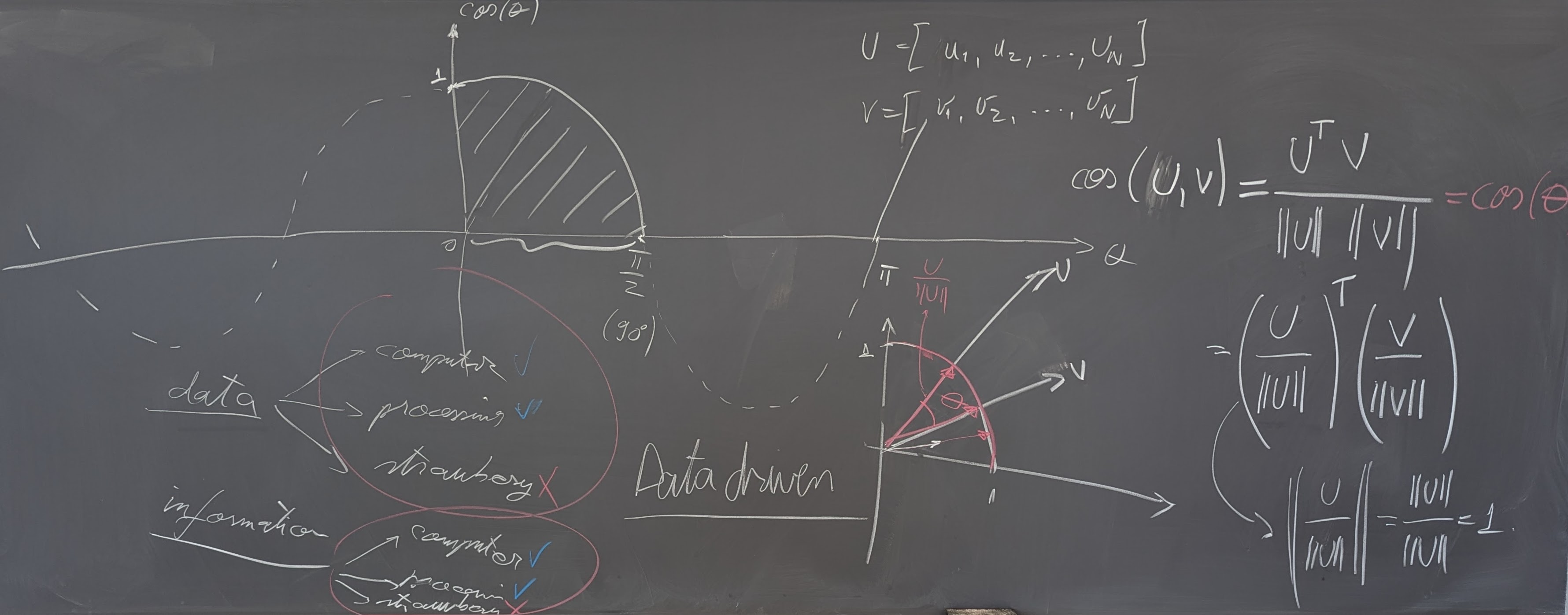
- Word meanings; Sparse vs. dense representations of words
- Chapter 5 on vector semantics and embeddings from the textbook.
- Notes from lecture on Feb 19: one and two.
- Notes from lecture on Feb 24: one, two, and three.
- Notes from lecture on Feb 26: one, two, and three.
- LLMs: use scenarios, strengths and weaknesses
- Chapter 7, sections on architectures, generation, and sampling.
- LLMs: application development through APIs
- LLMs: connecting applications with tools and external resources
- LLMs: Efficient Factual grounding using RAG and vector DBs
- LLMs: Connecting AI applications to external resources using MCP
- LLMs: developing and deploying multi-agent systems
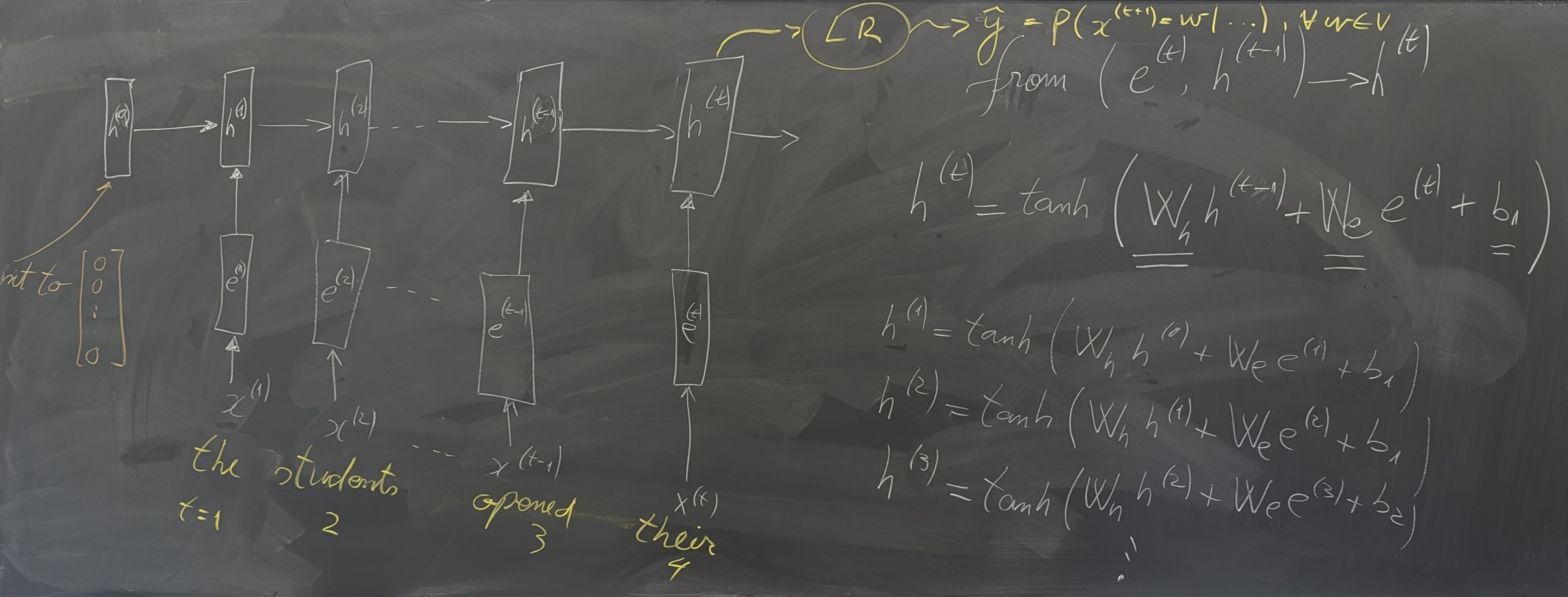
- N-grams and Neural models for Language Modeling and Sequence Processing
- Machine translation, Sequence-to-sequence models and Attention
- Transformers and Self-Attention
- Biases vs. fairness and rationality in NLP models
- Section 7.7 in J & M on Ethical and Safety Issues with Language Models
Homework assignments1:
- Assignment 0 on Python lists and strings.
- Assignment 1 on Word distributions.
- Assignment 2 on Wikipedia processing with regular expressions.
- Assignment 3 on Sentiment Analysis with Logistic Regression and engineered features.
- Assignment 4 on Vector Representations of Words.
- Assignment 5 on Question Answering on semi-structured restaurant data using the chat completion API with GPT, LLama, or Gemini.
- Assignment 6 on Restaurant Chatbot by interfacing LLMs with external tools.
- Assignment 7 on MCP client-server architecture for Restaurant Chatbot.
- Assignment 8 on Agentic Workflows for research, using planning and tools.
- Assignment 9 on RNNs for Sentiment Classification.
- Assignment 10 on Transformer-based models for NLP (optional).
Background reading materials:
Supplemental readings:
- Accurate methods for the statistics of surprise and coincidence, Ted Dunning, Computational Linguistics, 1993.
- Attention is all you need, Vaswani et al., NeurIPS 2017.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019.
- Durably reducing conspiracy beliefs through dialogues with AI, Costello et al., Science, September 2024.
- AI can help humans find common ground in democratic deliberation, Tessler et al., Science, October 2024.
Tools and packages:
- Natural language processing:
- Machine learning:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
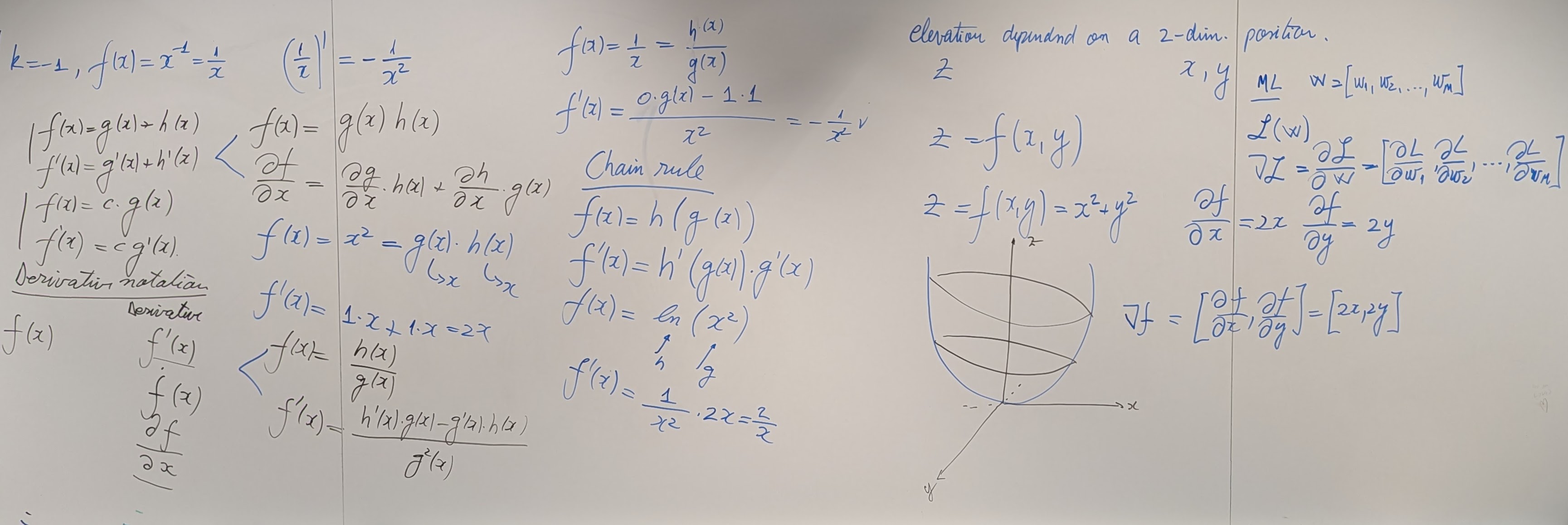{kind=link}
{kind=link}
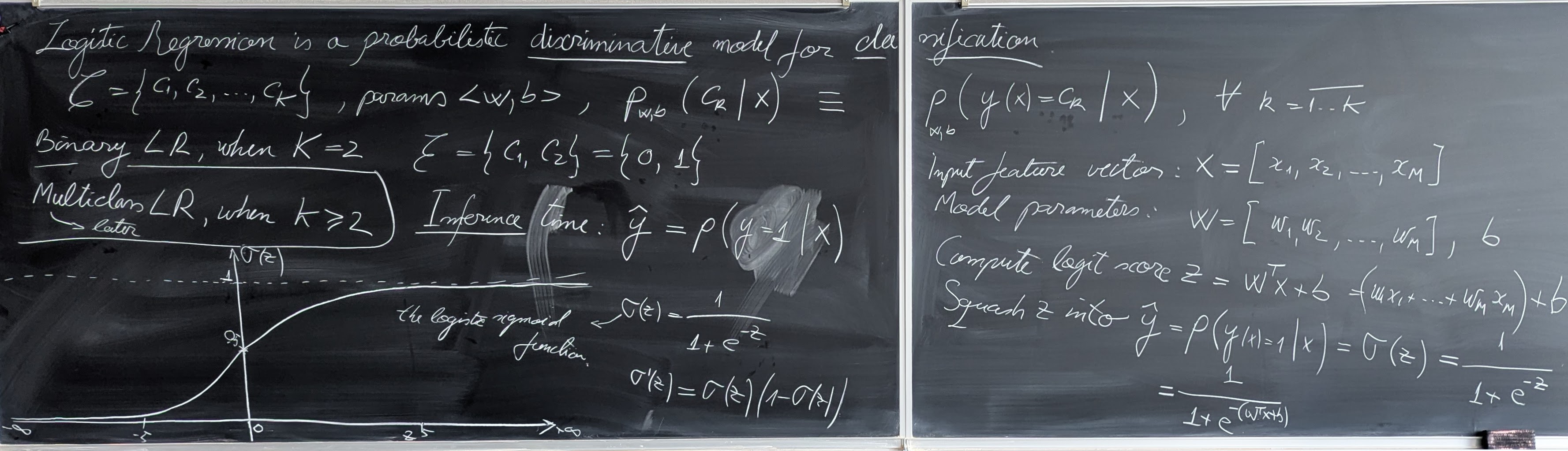{kind=link}
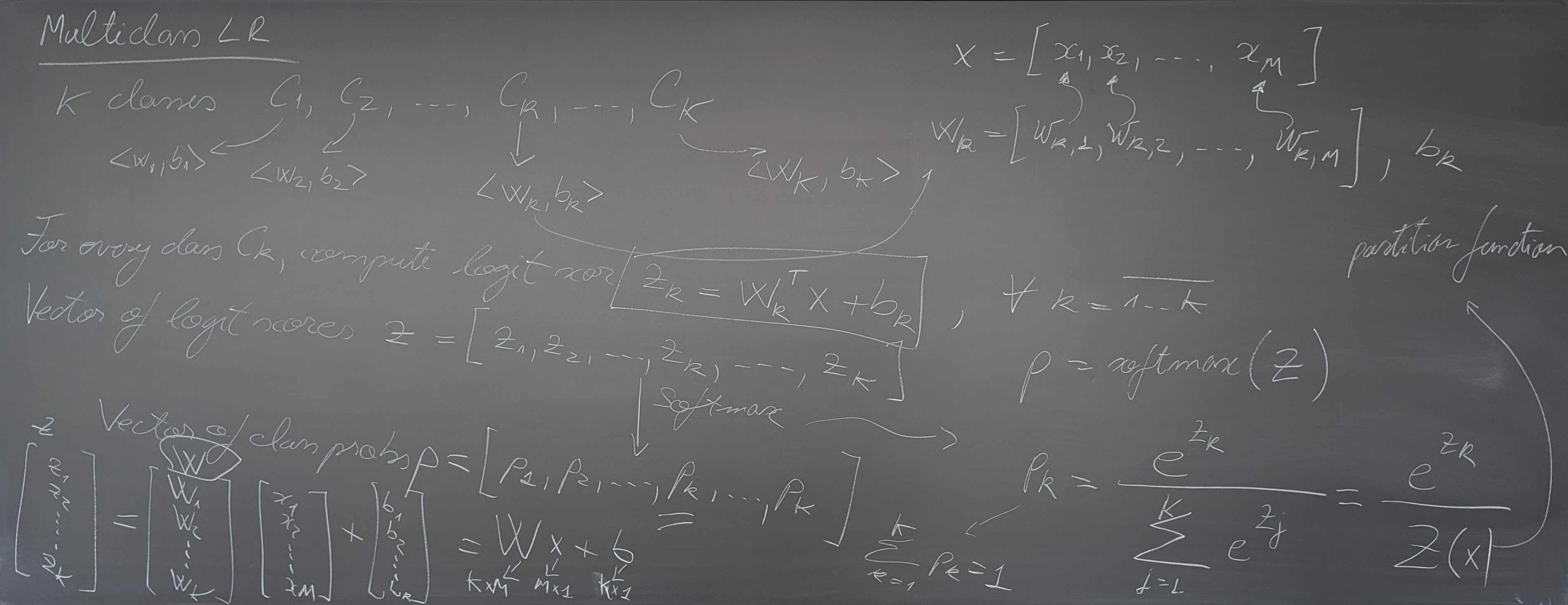{kind=link}
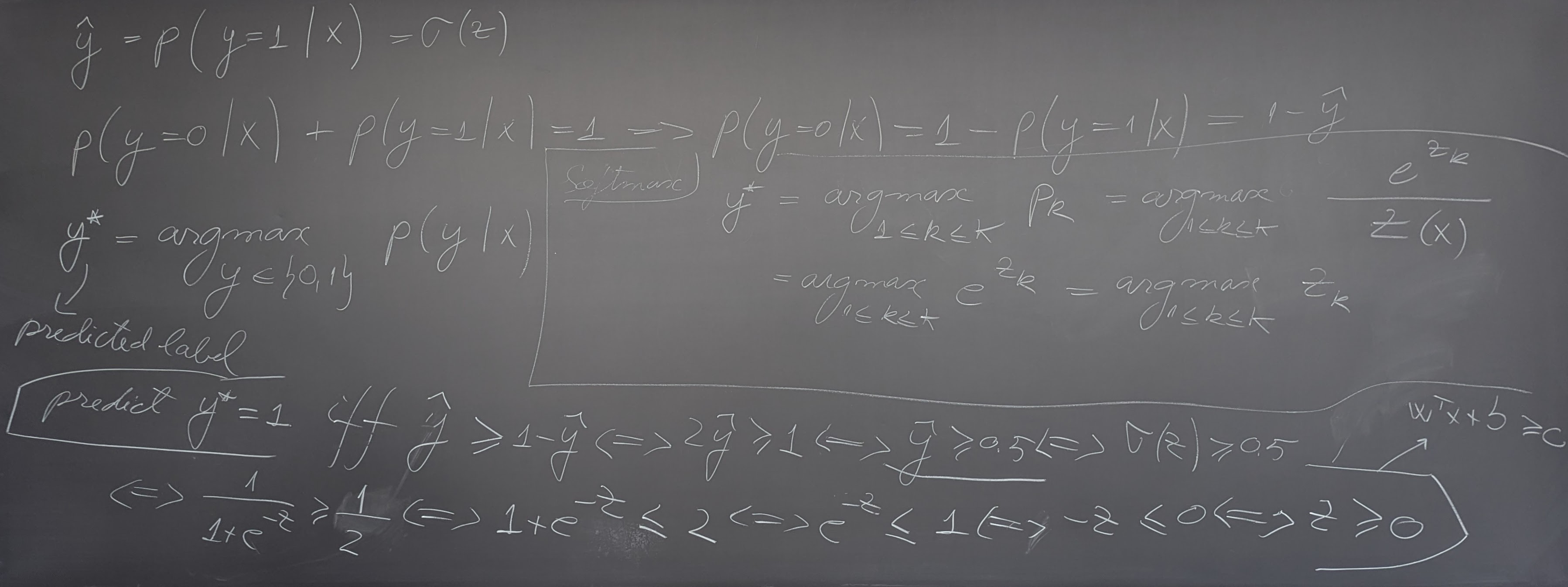{kind=link}
{kind=link}
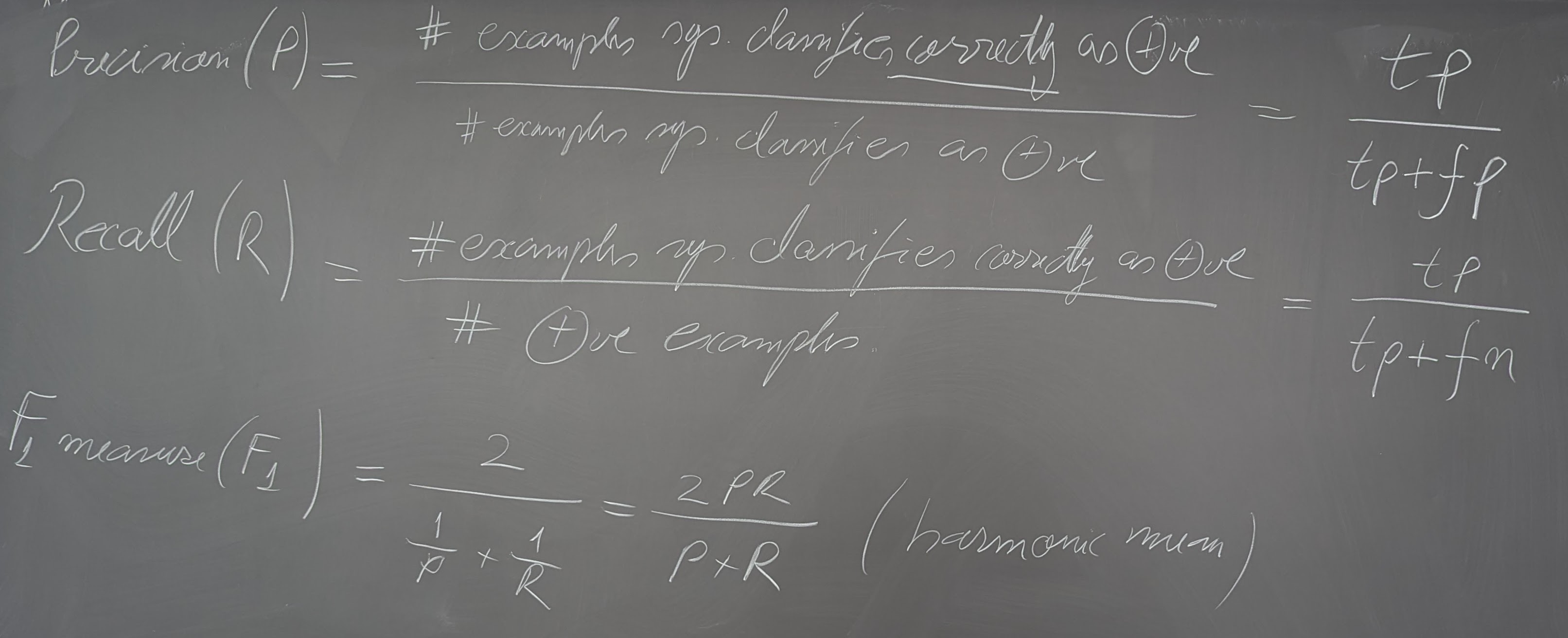{kind=link}
{kind=link}
{kind=link}
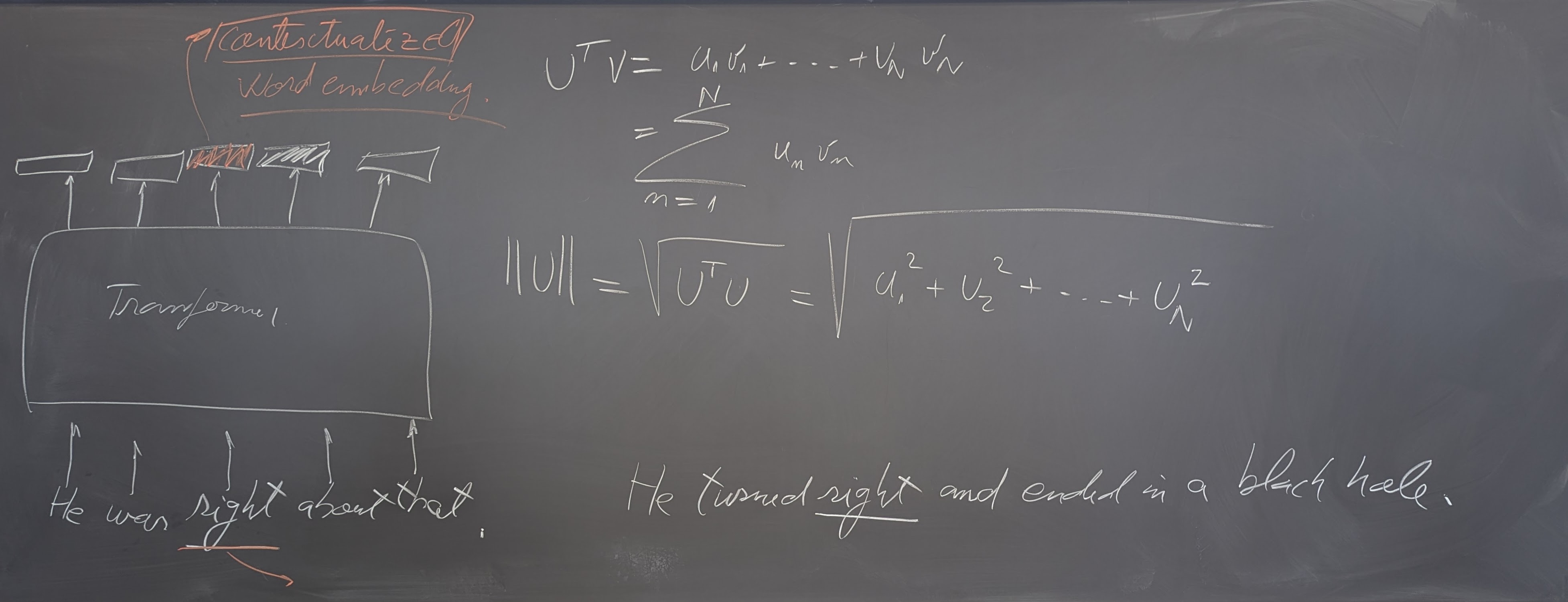{kind=link}
{kind=link}
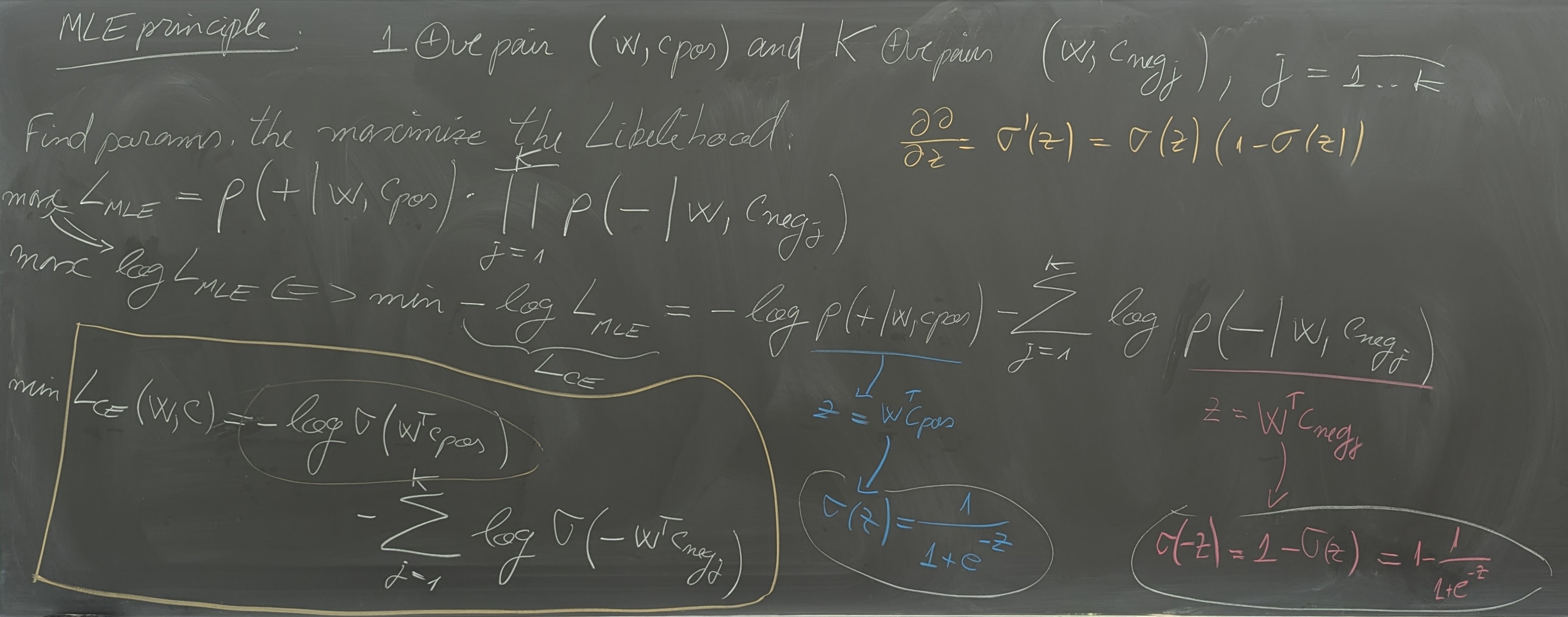{kind=link}
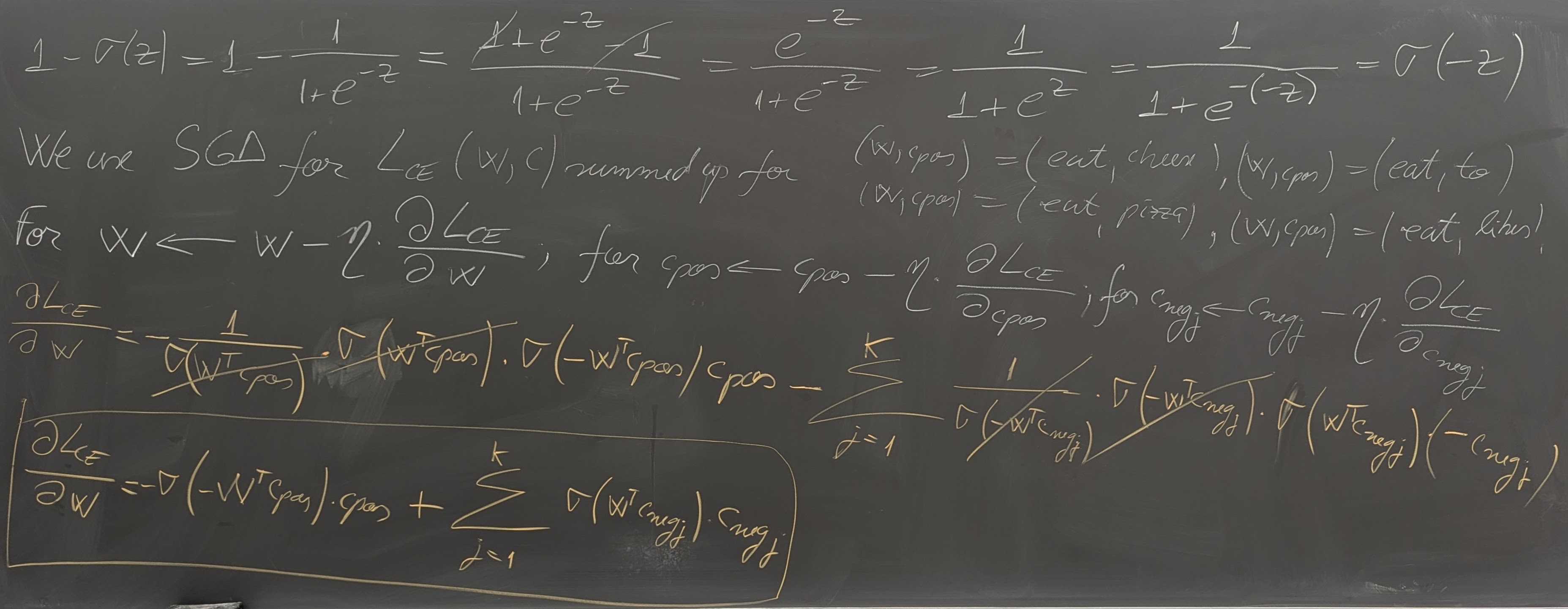{kind=link}
{kind=link}
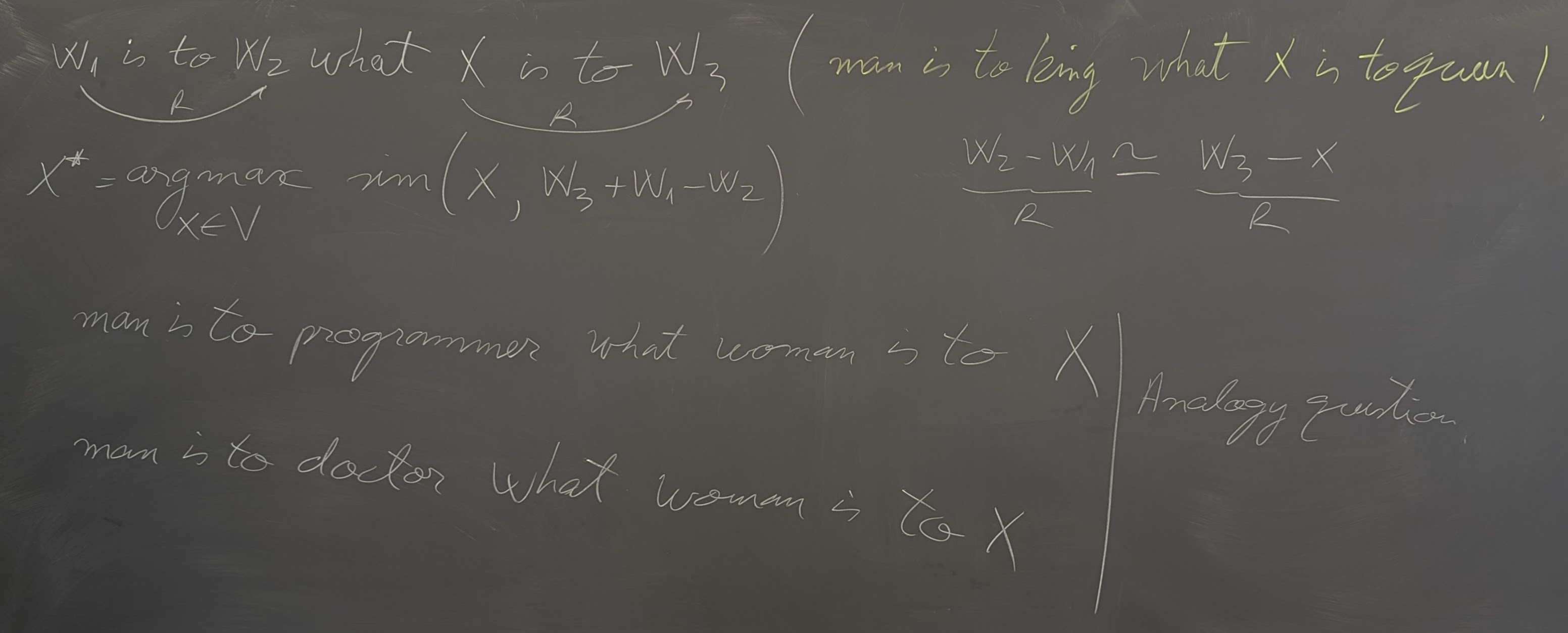{kind=link}
{kind=link}
{kind=link}
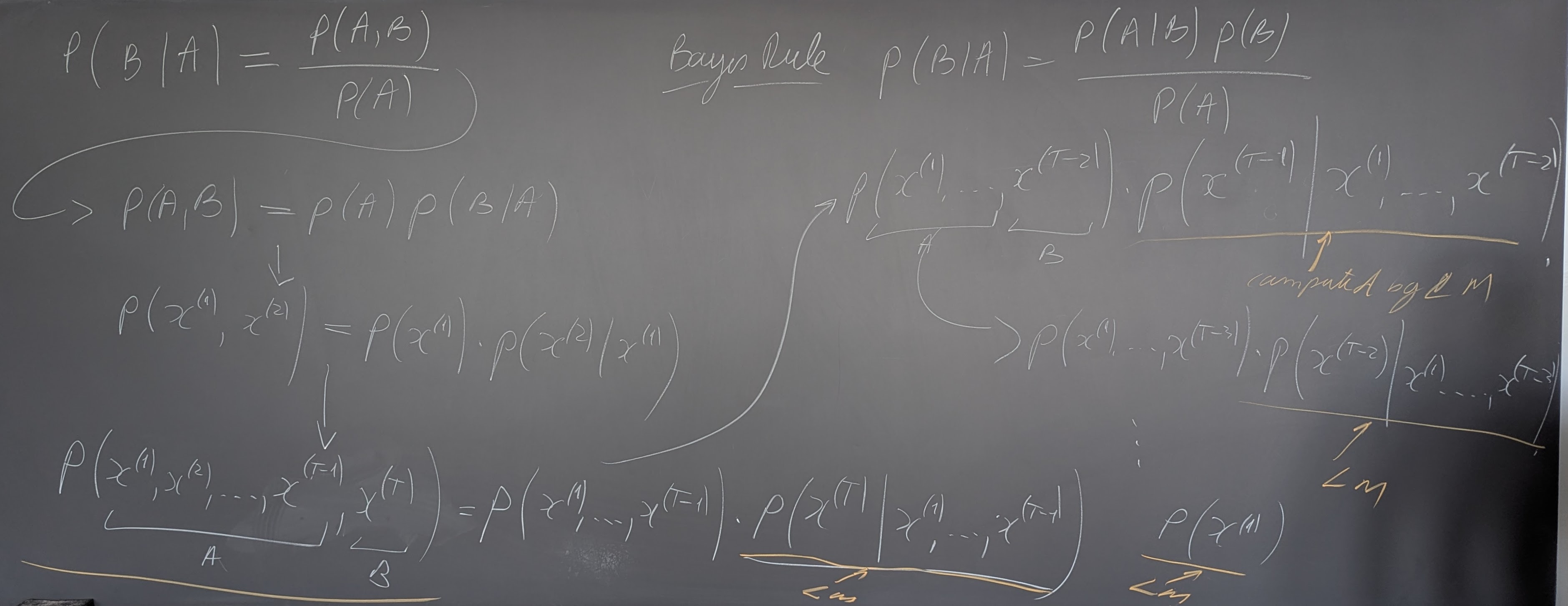{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
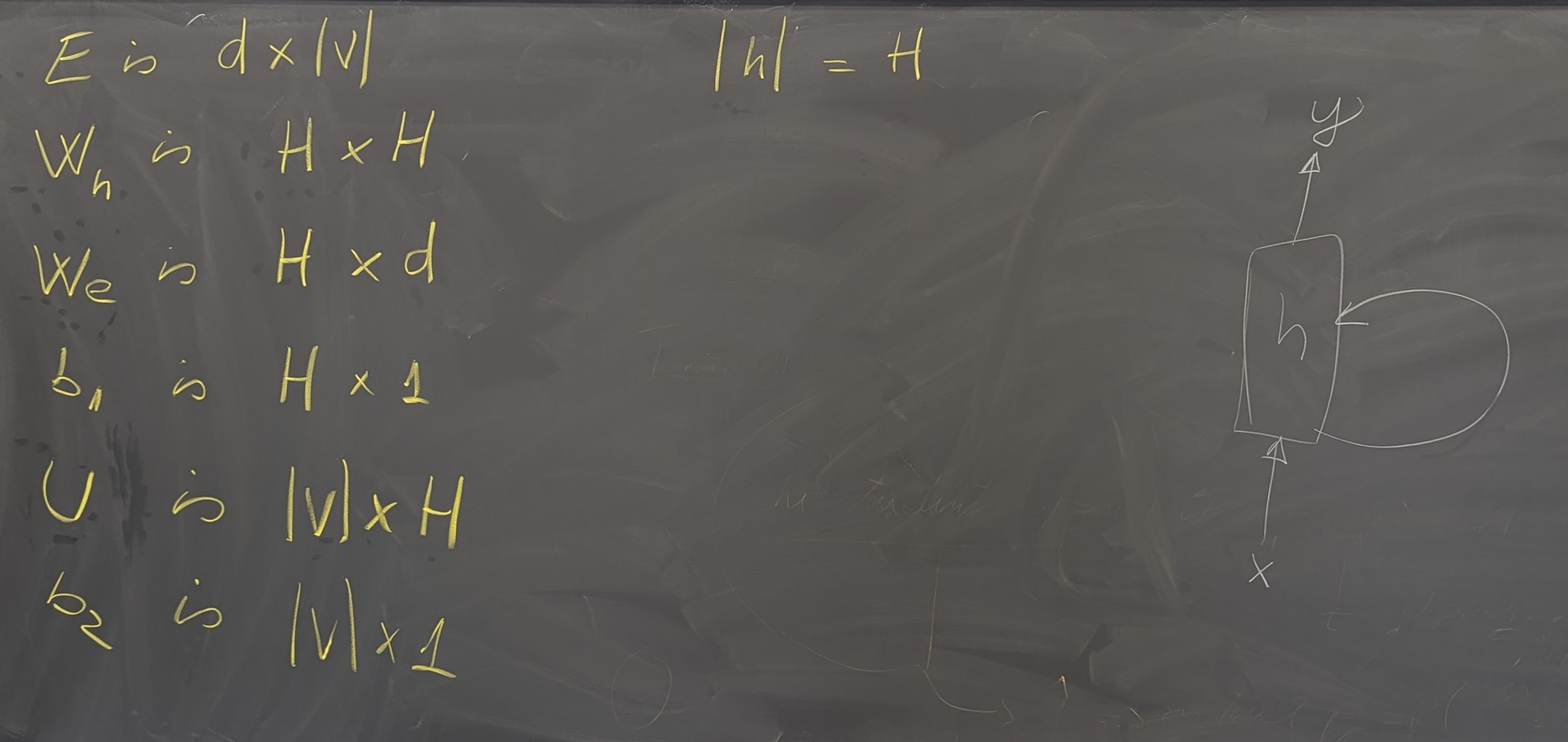{kind=link}
{kind=link}
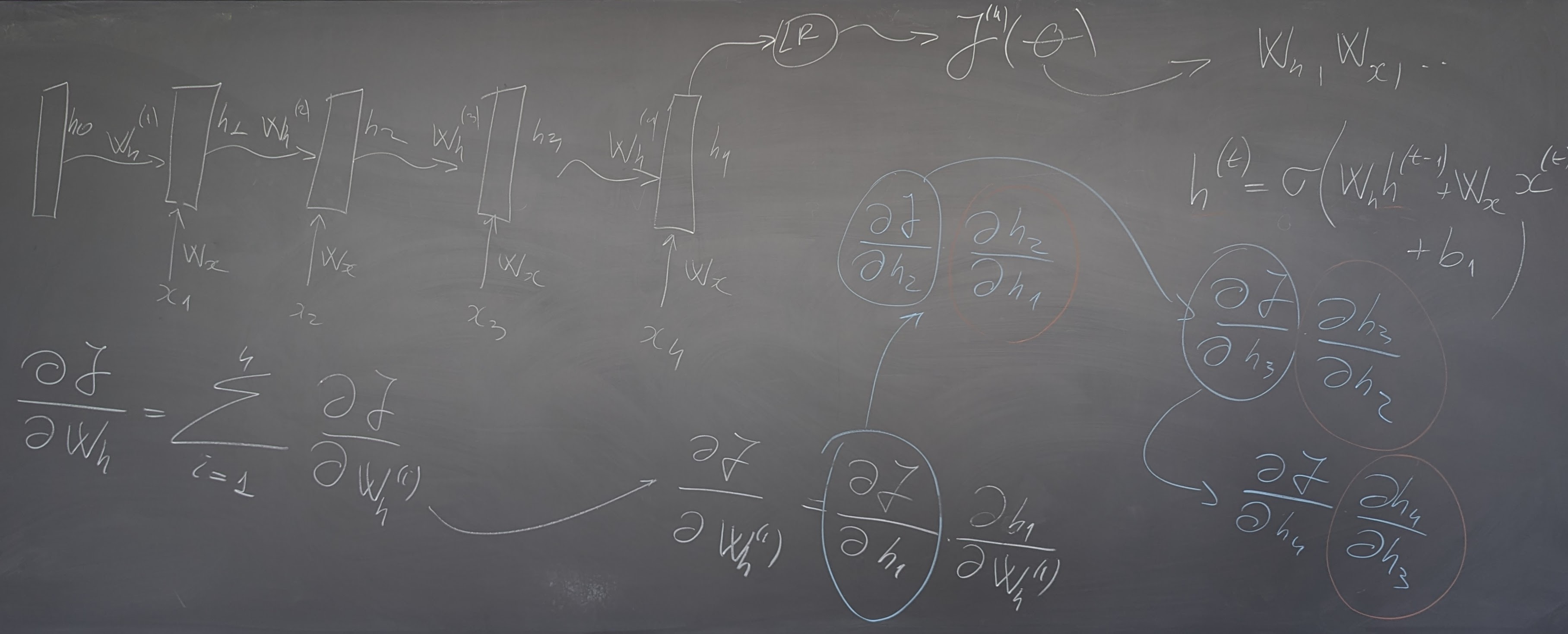{kind=link}
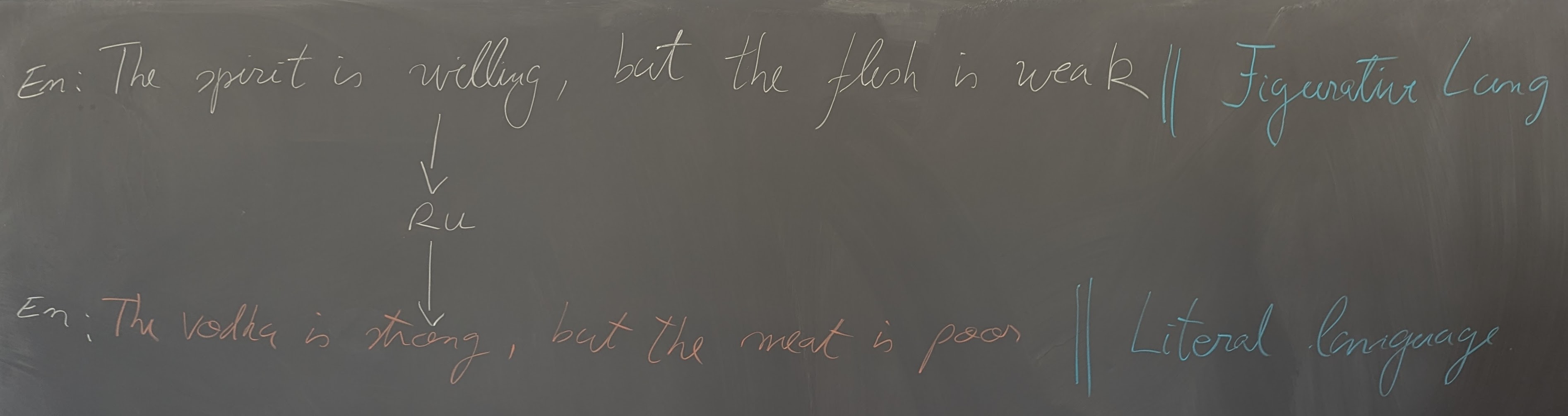{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}