Course description:
Natural Language Processing (NLP) is a branch of Artificial Intelligence concerned with developing computer systems that can analyze or generate natural language. This course will introduce fundamental linguistic analysis tasks, including tokenization, word representations, syntactic parsing, semantic parsing, and coreference resolution. Machine learning (ML) based techniques will be introduced, ranging from Naive Bayes and logistic regression to Transformer-based language models, which will be used in a number of NLP applications such as sentiment classification, information extraction, or question answering. Overall, the aim of this course is to equip students with an array techniques and tools that they can use to solve known NLP tasks, as well as new types of NLP problems.
Prerequisites:
Students are expected to be comfortable with programming in Python, data structures and algorithms (ITSC 2214), and have basic knowledge of linear algebra (MATH 2164), statistics, and formal languages (regular and context free grammars). Knowledge of machine learning will be very useful, though not strictly necessary. Relevant background material will be made available on this website throughout the course.
{kind=link}
{kind=link}
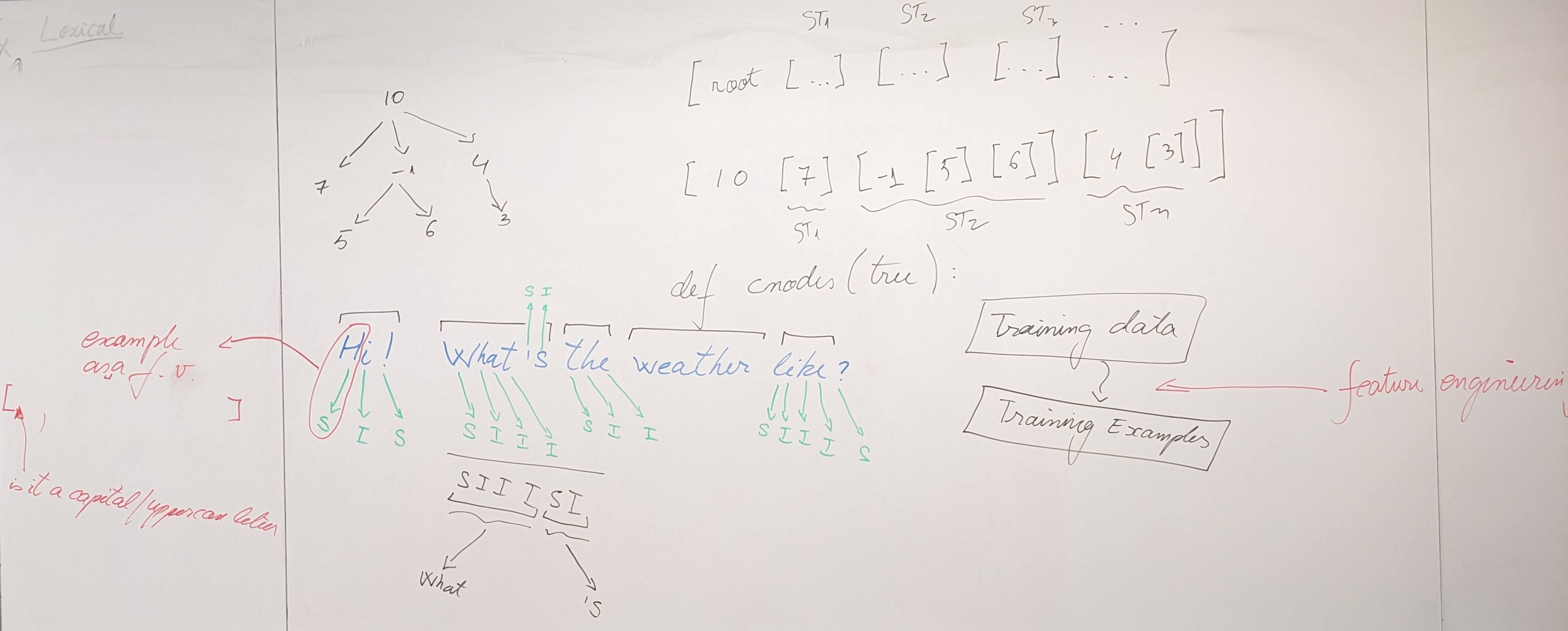{kind=link}
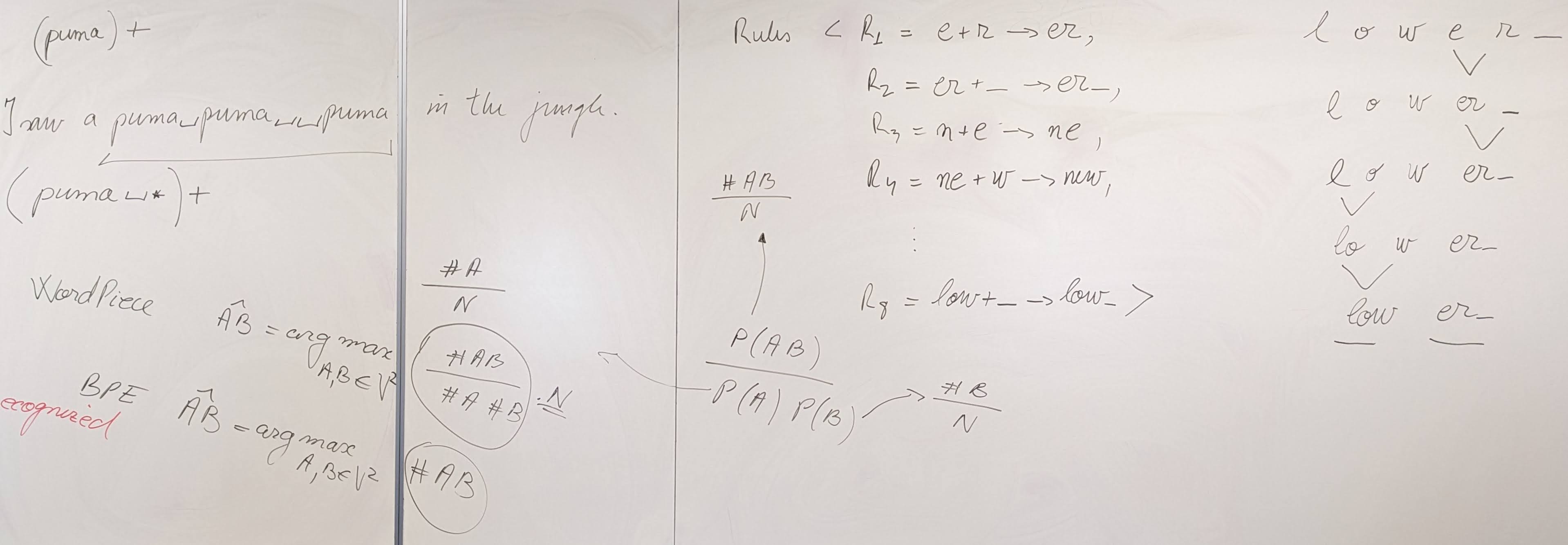{kind=link}
{kind=link}
{kind=link}
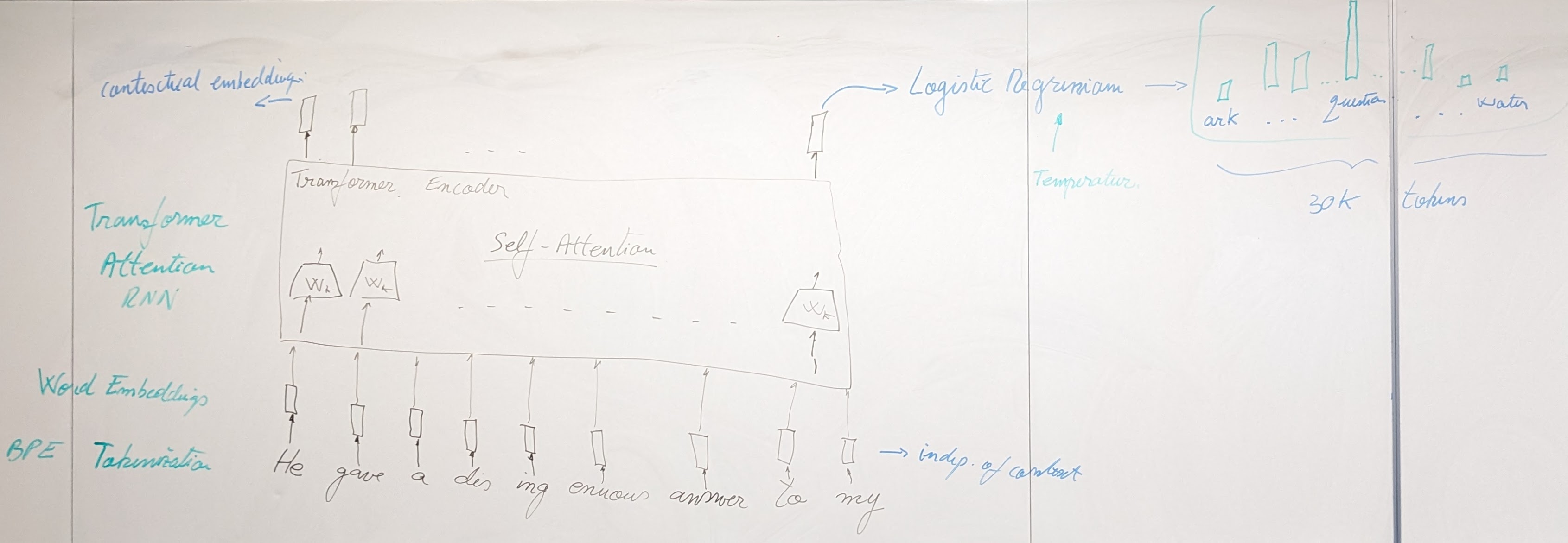{kind=link}
{kind=link}
{kind=link}
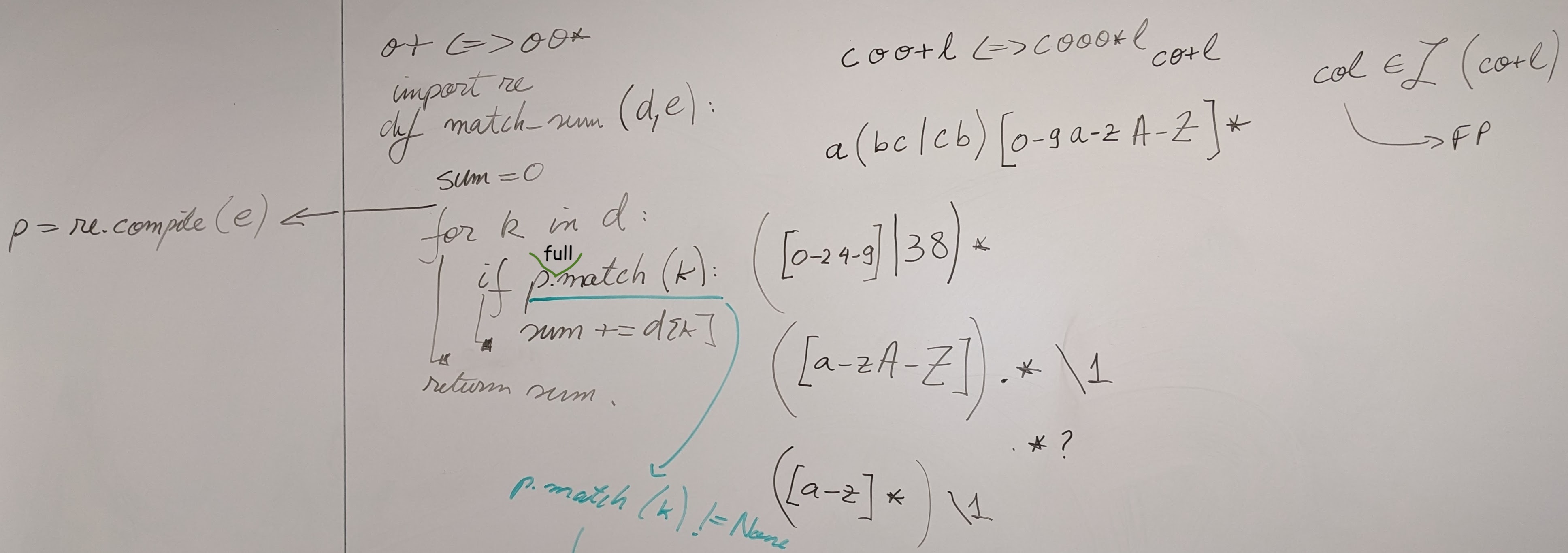{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
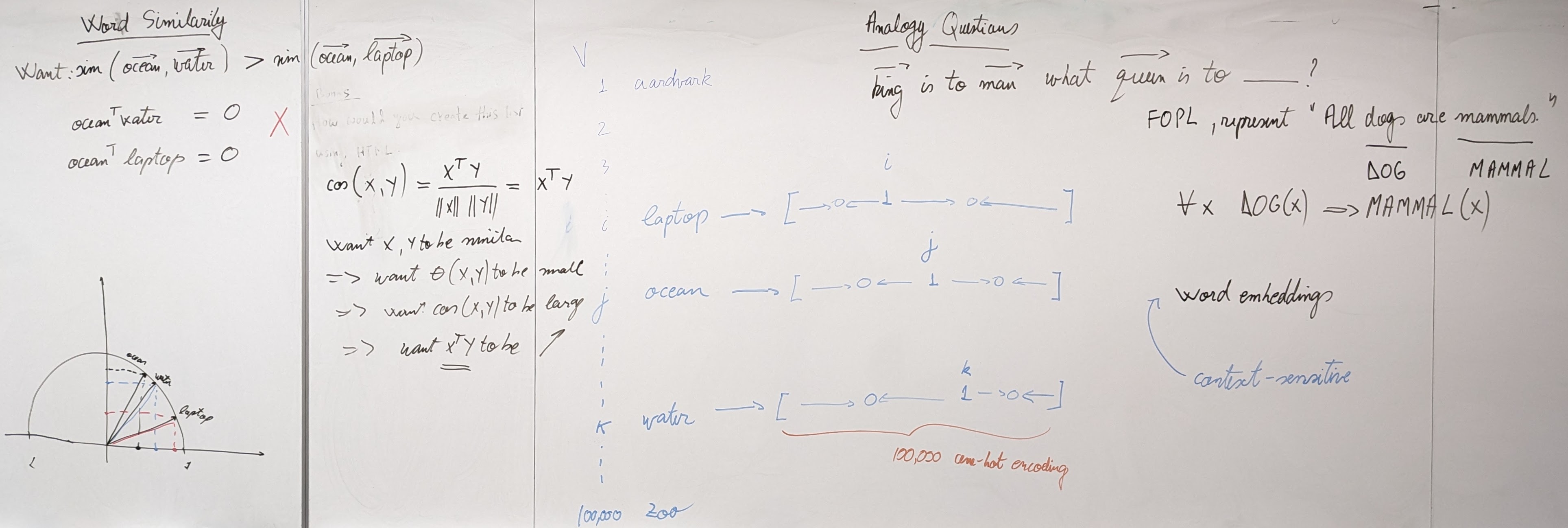{kind=link}
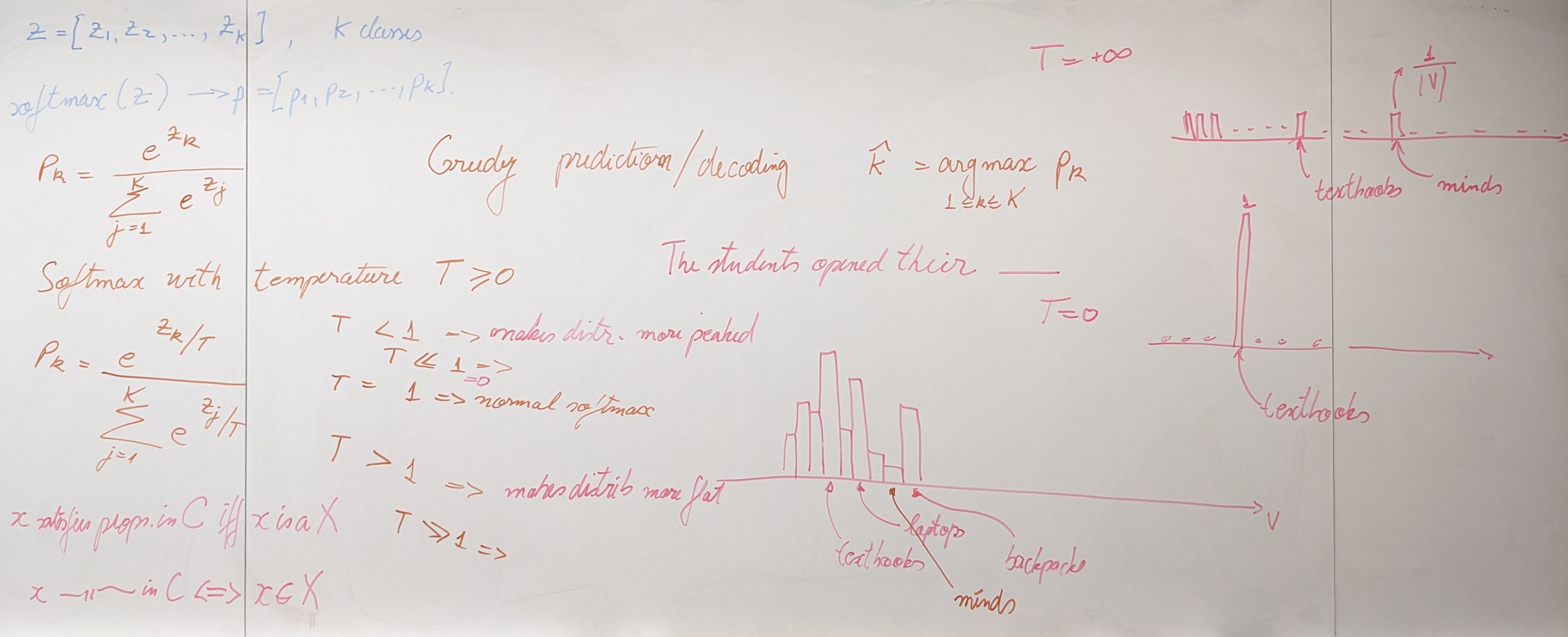{kind=link}
{kind=link}
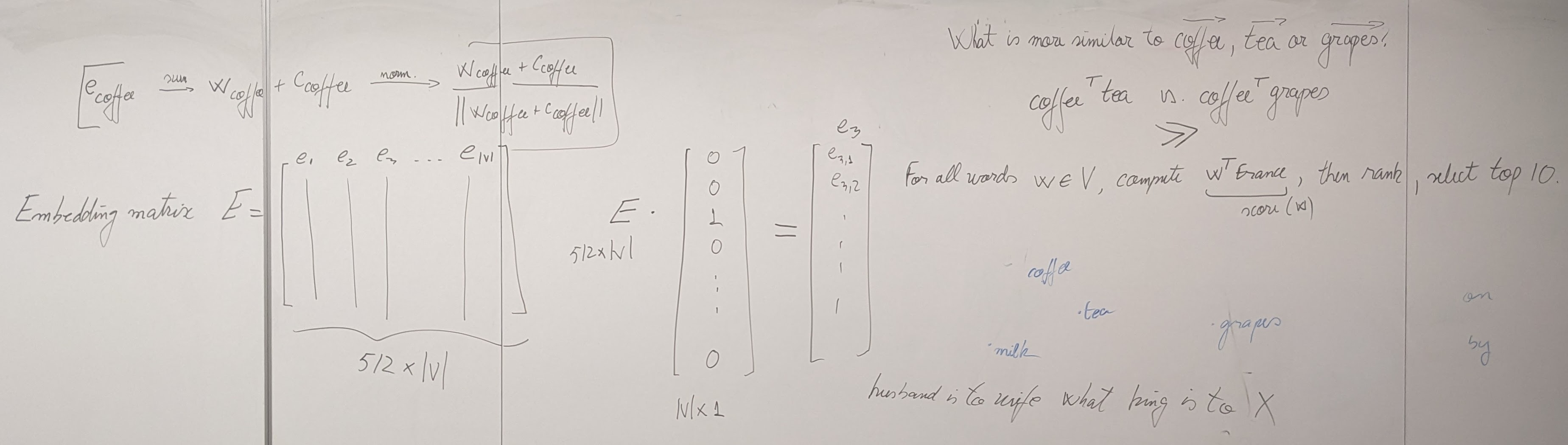{kind=link}
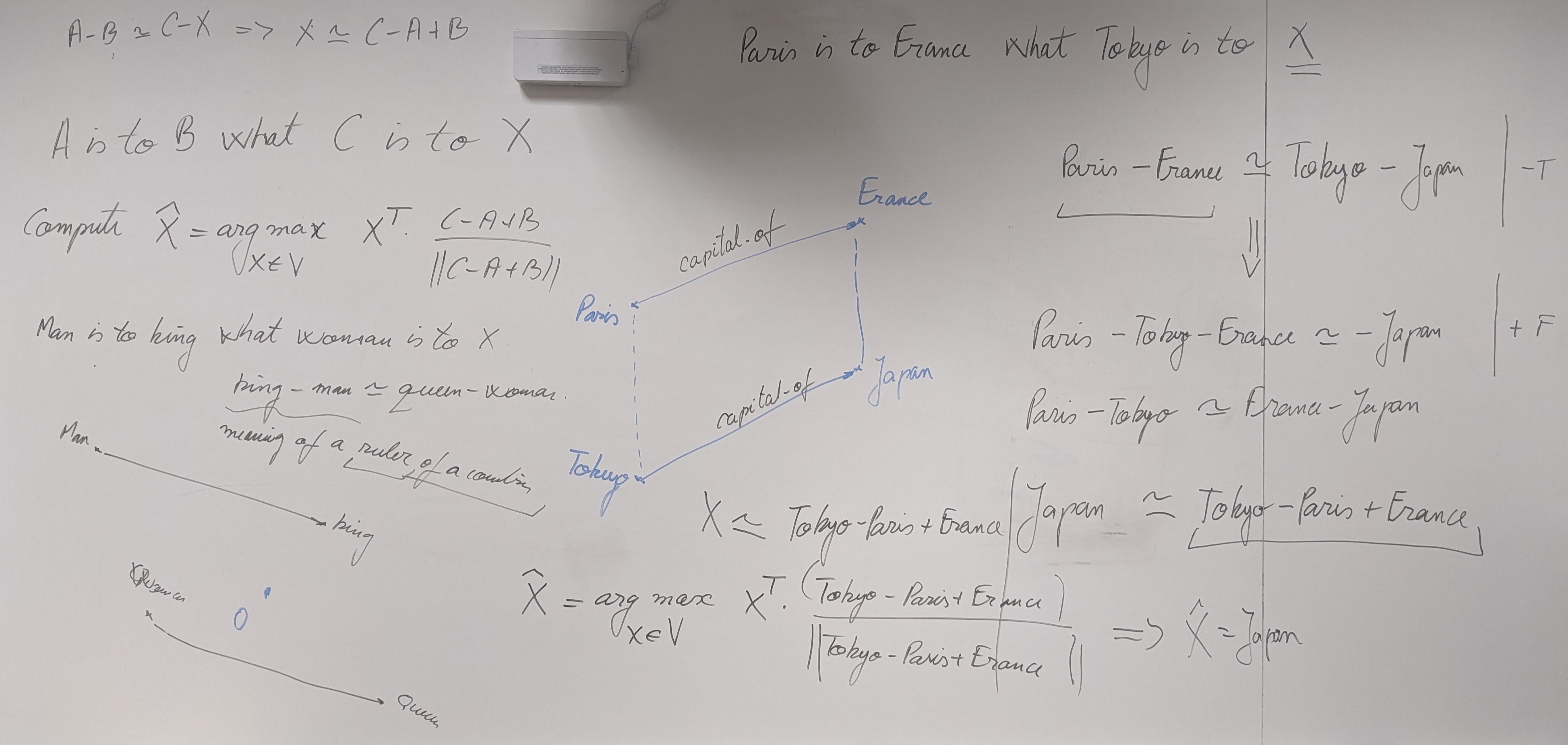{kind=link}
{kind=link}
{kind=link}
{kind=link}