CS 6890: Deep Learning
Spring 2020
Time and Location: Tue, Thu 1:30 – 2:50 pm, ARC 321
Instructor: Razvan Bunescu
Office: Stocker 341
Office Hours: Wed, Fri 3:00 – 4:00 pm, or by email appointment
Email: bunescu @ ohio edu
Textbook:
There is no required textbook for this class. Slides and supplementary materials will be made available on the course website.
Supplemental deep learning resources:
CSC 421: Neural Networks and Deep Learning @ Toronto, 2019.
CS 231n: Convolutional Neural Networks for Visual Recognition @ Stanford, 2019.
CS 498: Introduction to Deep Learning Svetlana Lazebnik @ Illinois, 2018.
Deep Learning by Ian Goodfellow, Yoshua Bengio and Aaron Courville. MIT Press, 2016.
Deep Learning course sequence @ Coursera.
Dive into Deep Learning by Zhang, Lipton, Li, and Smola. Amazon, 2019.
Machine learning introductions:
Machine Learning @ Ohio course website.
Machine Learning @ Coursera video lectures and exercises.
Machine Learning @ Stanford video lectures and exercises.
Course description:
This course will introduce the multi-layer neural networks, a common deep learning architecture, and gradient-based training through the backpropagation algorithm. Fully connected neural networks will be followed by more specialized neural network architectures such as convolutional neural networks, recurrent neural networks with attention, and deep generative models. The later part of the course will explore more advanced topics, such as adversarial examples, deep reinforcement learning, and interpretability. The lectures will cover theoretical aspects of deep learning models, whereas homework assignments will give students the opportunity to build and experiment with shallow and deep learning models, for which skeleton code will be provided.
Proposed topics:
Logistic and Softmax Regression, Feed-Forward Neural Networks, Backpropagation, Vectorization, PCA and Whitening, Deep Networks, Convolution and Pooling, Recurrent Neural Networks, Long Short-Term Memory, Gated Recurrent Units, Neural Attention Models, Sequence-to-Sequence Models, Distributional Representations, Variational Auto-Encoders, Generative Adversarial Networks, Deep Reinforcement Learning.
Prerequisites:
Previous exposure to basic concepts in machine learning, such as: supervised vs. unsupervised learning, classification vs. regression, linear regression, logistic and softmax regression, cost functions, overfitting and regularization, gradient-based optimization. Experience with programming and familiarity with basic concepts in linear algebra and statistics.
Lecture notes:
- Syllabus & Introduction
- Linear Regression, Logistic Regression, and Vectorization
- Gradient Descent algorithms
- Linear algebra and optimization in NumPy and PyTorch
- Feed-Forward Neural Networks and Backpropagation
- Unsupervised Feature Learning with Autoencoders
- Introduction to Automatic Differentiation, invited lecture by Dr. David Juedes.
- PCA, PCA whitening, and ZCA whitening
- Convolutional Neural Networks
- Word Embeddings
- Natural Language Processing (Almost) from Scratch, Collobert, Weston, Bottou, Karlen, Kavukcuoglu, and Kuksa, JMLR 2011.
- Distributed Representations of Words and Phrases and their Compositionality, Mikolov, Sutskever, Chen, Corrado, and Dean, NIPS 2013.
- Character-Aware Neural Language Models, Kim et al., AAAI 2016.
- Recurrent Neural Networks
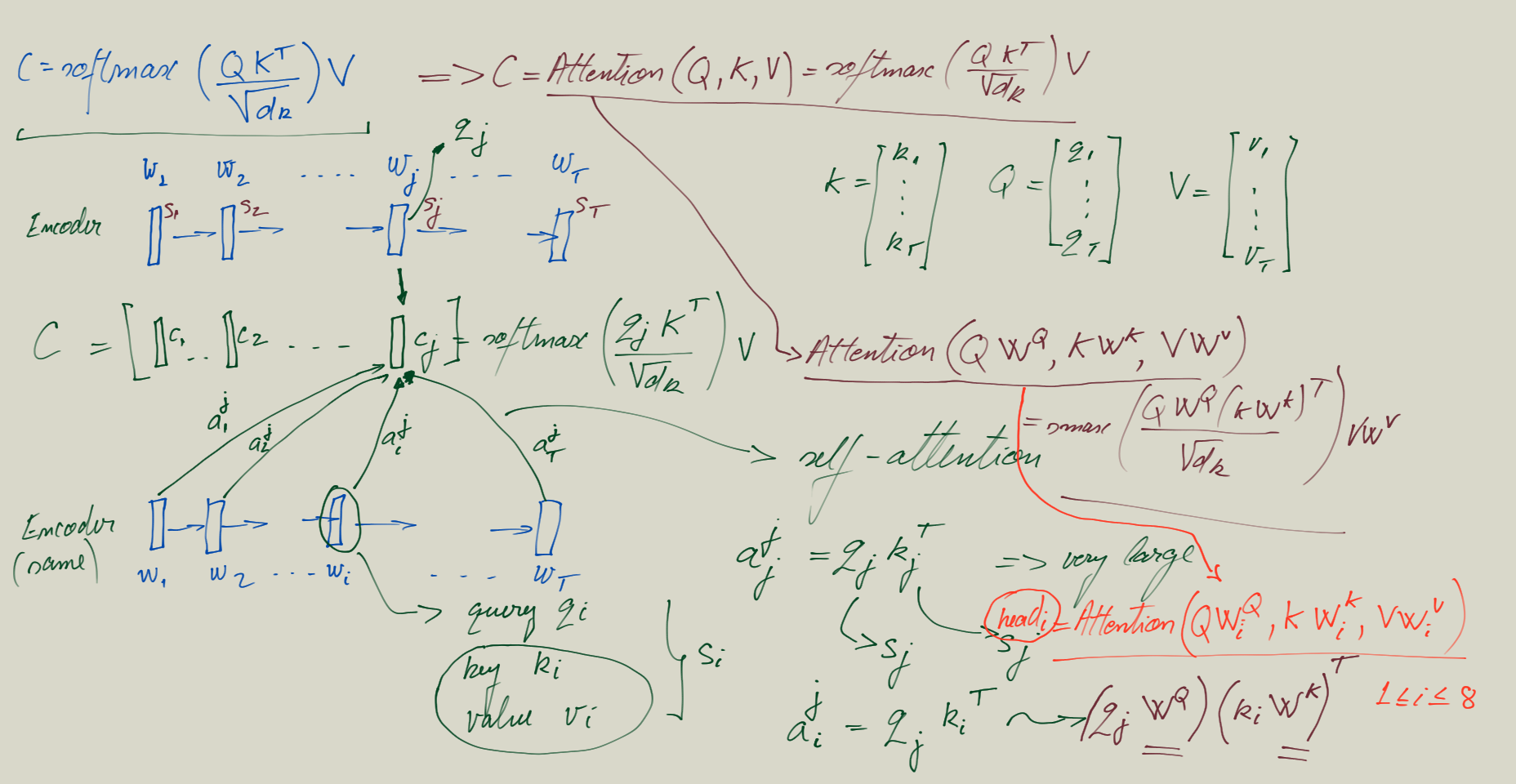
- RNNs with Attention for Machine Translation
- From RNNs to Transformer
- ELMo: Deep contextualized word representations, Peters et al., NAACL 2018.
- Transformer: Attention is all you need, Vaswani et al., NIPS 2017.
- GPT: Improving Language Understanding by Generative Pre-Training, Radford et al., OpenAI 2018.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin et al., NAACL 2019.
- Deep Generative Models
Homework assignments1,2:
- Assignment and code.
- Assignment and code.
- Assignment, code and data.
- Assignment, code and data.
- Assignment, code, word2vec Google News embeddings, and the Stanford Natural Language Inference (SNLI) dataset.
Paper Presentations
Final Project:
Online reading materials:
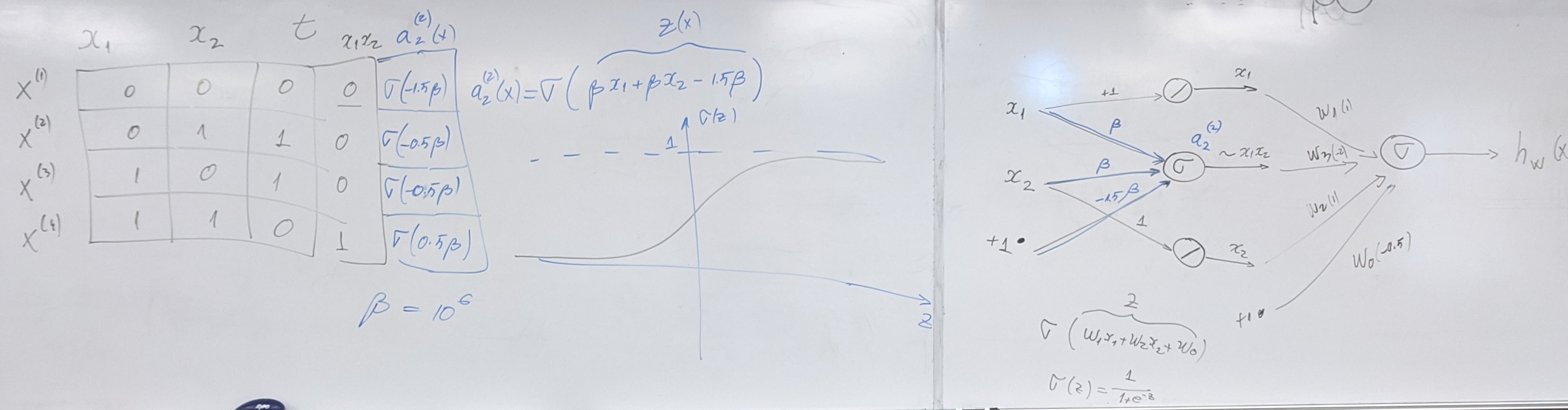{kind=link}
{kind=link}
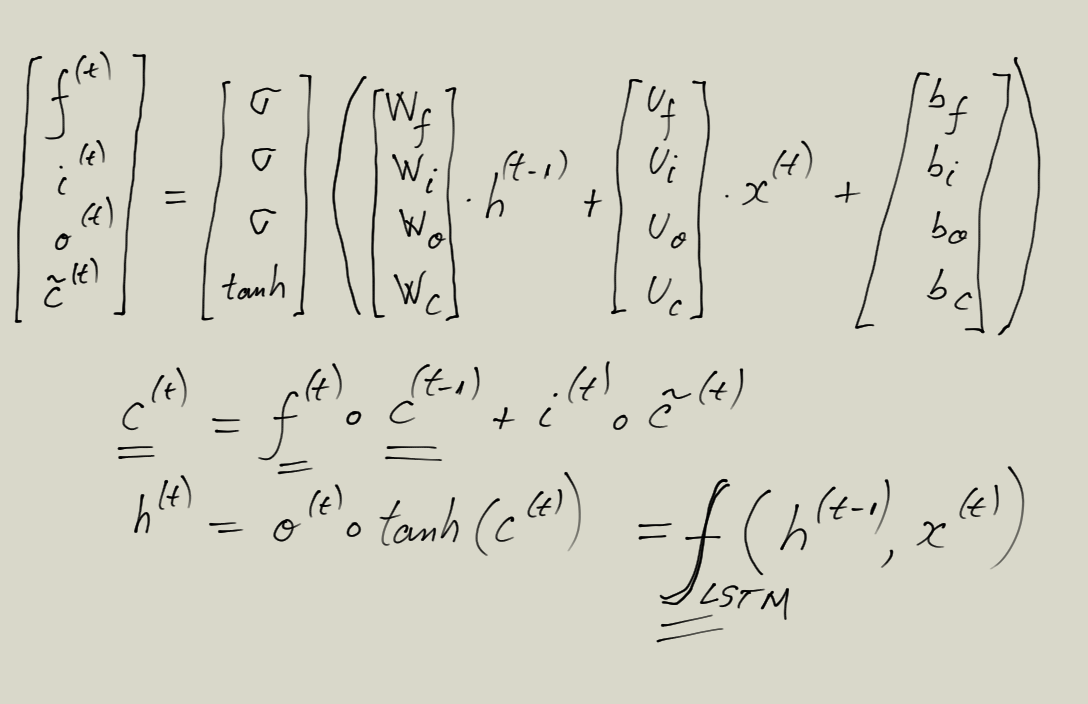{kind=link}
{kind=link}
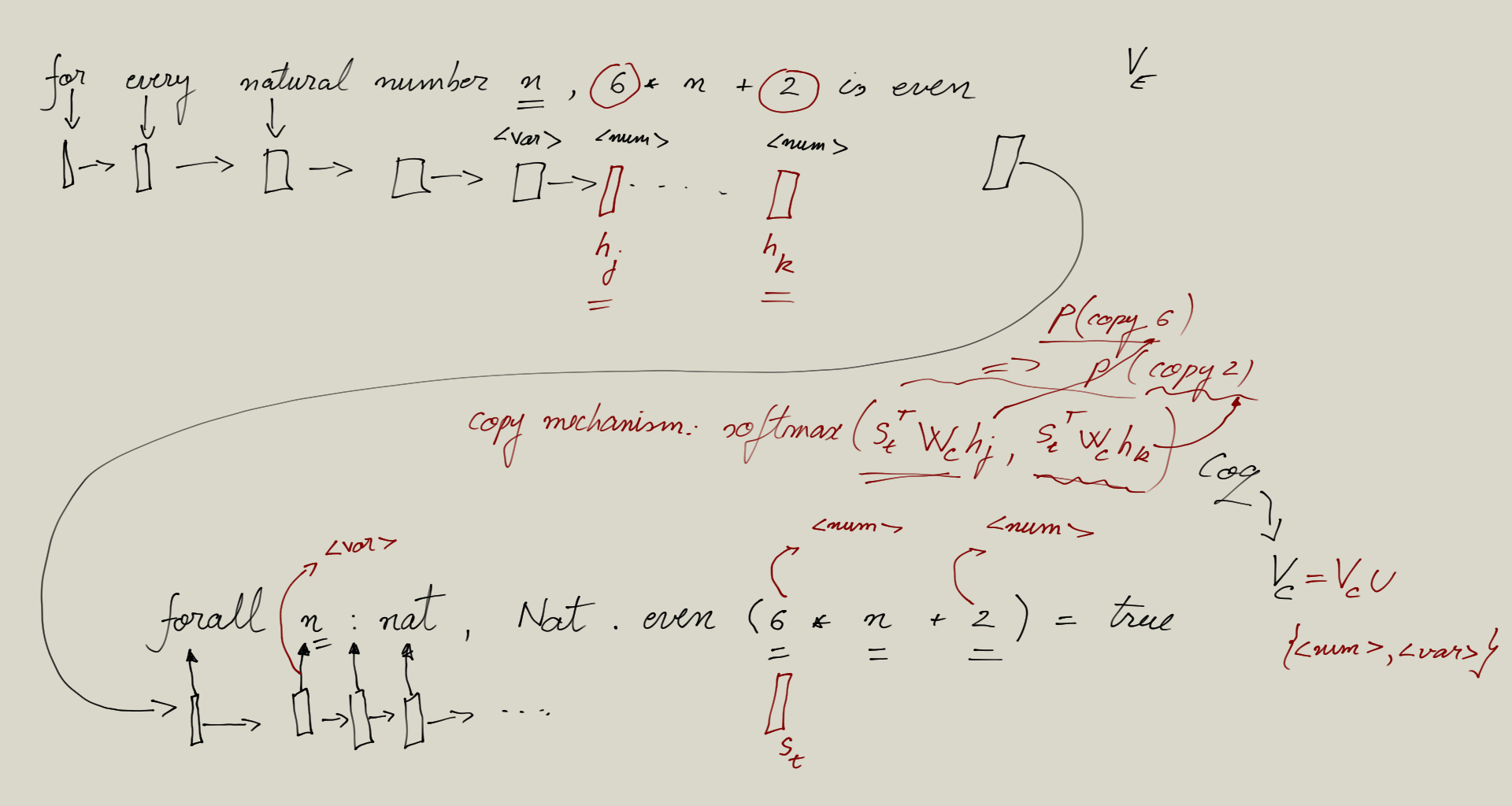{kind=link}
{kind=link}
{kind=link}
{kind=link}